
regex
POSIX, PCRE
regex에는 여러 변종이 있지만, 2가지가 가장 유명하다.
- POSIX REGEX
- UNIX 계열 표준 정규표현식
- BRE(basic RE), ERE(Extended RE)
- BRE : basic REGEX - grep이 작동되는 기본값
- ERE : extended REGEX - 좀더 많은 표현식과 편의성을 제공
- meta character중에 ERE라고 적힌 것을 의미
- 이것이 공통이고, 표준이므로 이를 먼저 배워야 한다.
- PCRE
- Perl 정규표현식 호환으로 확장된 기능을 가짐
- C언어 기반으로 시작하는데, POSIX REGEX보다 성능이 좋은
- 실무에서도 이를 많이 쓰고, 대부분의 다른 python이나 등등의 언어는 이를 기준으로 작성됨
- 현재는 PCRE2 버전을 사용
+ EBNF
*,+,?,[…] 등은 EBNF의 영향이 크다. EBNF를 알고 있다면 학습이 쉬워지기 때문에 EBNF는 필수로 알아야 한다. XML같은 마크업 언어 및 대부분의 설정 포맷은 EBNF를 기준으로 쓰인다.
command line utility
grep (global regular expression print)
- 유닉스에서 가장 기본적인 REGEX평가 유틸리티
- 정규식을 평가할 수 있는 유틸리티
sed (stream editor)
- REGEX 기능을 일부 탑재하고 있다.
- 스트림 에디터
awk
- REGEX뿜나 아니라 문자열 관련 방대한 기능을 가진 프로그래밍 언어
- 패턴식을 다룰 수 있는 언어툴
- 제일 많은 기능을 가짐
- 실무에서 실제 많이 사용되는 것
grep → sed → awk 순으로 공부하는 것이 좋다.
grep
matcher:
- -G : BRE를 사용하여 작동 (기본값) (기본이라 잘 안쓰임)
- -E : ERE를 사용하여 작동, egrep으로 작동시킨 것과 같다.
- -P : PCRE를 사용하여 작동, pcre2grep으로 작동시킨 것과 같다.
- -F : 고정길이 문자열을 탐색하는 모드, fgrep과 같음, 속도가 빠른 것이 장점 (잘안씀)
option
- —color : matched 된 부분을 강조하여 색깔
- -o : 매칭에 성공한 부분만 잘라서 보여줌
- -e PATTERN : 패턴 여러개 연결했을 때 사용하긴 함 (잘안씀)
-v, —invert-match : 검색에 실패한 부분만 봄
- meta character
| 번호 | 이름 | 기호 | 설명 |
|---|---|---|---|
| ⑴ | 문자 지정 | . | 임의의 문자 한 개를 의미 |
| ⑵ | 반복 지정 | ? | 선행문자패턴이 0 or 1개 나타난다. (ERE) |
| ⑶ | 반복 지정 | + | 선행문자패턴이 1개 이상 반복된다. (ERE) |
| ⑷ | 반복 지정 | * | 선행문자패턴이 0개 이상 반복된다. |
| ⑸ | 반복 지정 | {m,n} | interval, 반복수를 직접 지정할 수 있다. (ERE) |
| ⑹ | 위치 지정 | ^ | 라인의 앞부분을 의미한다. |
| ⑺ | 위치 지정 | $ | 라인의 끝부분을 의미한다. |
| ⑻ | 그룹 지정 | […] | 안에 지정된 문자들 그룹 중에 한 문자를 지정 |
| ⑼ | 그룹 지정 | [^…] | 안에 지정된 그룹의 문자를 제외한 나머지를 지정 |
| ⑽ | 기타 | \ | escape, 메타의 의미를 없앤다. |
| ⑾ | 기타 | | | alternation, choice, or연산을 한다 (ERE) |
| ⑿ | 기타 | () | 괄호는 패턴을 그룹화 및 백레퍼런스 작동을 한다. (ERE) |
escape란 메타의 의미를 잃는다는 것으로 실제 ., ?, + 등이 포함된 것만 추출한다는 것이다.
- 반복 지정 (2~4)
- 수량자는 선행문자패턴(atom이라 부름)을 수식하는 기능을 가진다.
- ? : x?ml ⇒ xml, ml
- * : can* ⇒ ca, can, cann, cannn, …
* 은 곱셈이라서 0부터
C* : C * 0 = null, C * 1 = C
- + : can+ ⇒ can, cann, cannn, …
+ 는 덧셈이라서 1부터
C+ : C + 0 = C, C+ 1개의 C = CC
- {}(interval) : abc{2,5} : abcc, abccc,abcccc,abccccc
- m과 n은 생략 가능하다. {n}, {m,}, {,n}
그러나 이 *(kleene star)은 최소 null과 매칭되므로 backtracking으로 느려지는 원인이 될 수 있다.
- 위치 지정 (8 ~ 9)
^, $ 는 패턴의 위치를 지정하는 패턴이다.
- ^asd : asd로 시작하는 행
- ^$ : 비어있는 행
- <BR>$ : <BR>로 끝나는 경우
- 그룹 지정 (10 ~ 11)
[] , [^ ] 는 character class
- [abcd] : a,b,c,d 중에 하나
- [0-9] : 0~9
- [a-zA-Z0-9] : 대소문자 알파벳과 숫자
- [^0-9] : [0-9]를 제외한 나머지
- ^ 자체를 그룹에 넣으려면 [ 이것 바로 뒤에 오지만 않으면 된다. \⇒ [0-9^]
- 또는 escape 시켜도 된다.
p[abcd]\+ous : p 바로 뒤부터 abcd 중에서만 추출하는데 1개 이상인 것, 그리고 ous로 마무리 -> opacous, opacousness
이 때, grep에서 ERE문법을 사용하기 위해서는 \를 추가해서 작성해야 한다. 그러나 egrep에서는 그냥 작성하면 된다. ERE문법이 아닌 것에 \를 추가하면 이는 문자 자체로 인식하게 만드는 역할을 한다.
실습
log data와 grep을 묶어서 사용할 수 있다.
1
2
3
# grep --color pam_systemd exjournal.log
# grep --color -A 1 "pam_systemd" exjournal.log
여기서 -A 1는 after 즉, 찾은 것 다음에 1줄을 더 출력하겠다. -B는 before ,-C는 이 둘을 더한 것
-C 1 == -A 1 -B 1
greedy matching
pattern은 최대한 많은 수의 매칭을 하려고 하는 성질이 있다.
1
2
3
$ var2="It's a gonna be <b>real</b>It's gonna <i>change everything</i> I feel"
$ echo $var2 | egrep -o "<.+>"
<b>real</b>It's gonna <i>change everything</i>
여기서 ., 즉 문자 1개이상이 포함되어 있는 것을 추출하는데, 최대한 많은 수의 매칭을 하려고 하기 때문에 <b></b>처럼 작은 단위가 아닌 <b>~</i>까지 모두를 추출한 것이다.
그래서 이 greedy matching 성질 때문에 처음에는 큰 범위로 불러온 후 점점 좁혀나가는 것이 좋은 방법이다.
방금 조건처럼 크게 된 이유는 .일 것이다. 그래서 <b>,</b>만 추출하려면 이것을 다른 것으로 바꾸어 표현하게 된다면 <>를 제외하고 <+>를 보면
1
2
3
4
5
$ echo $var2 | egrep -o "<[^<>]+>"
<b>
</b>
<i>
</i>
non-greedy matching
greedy matching과 반대대는 개념으로 <[^<>]+>를 사용하면 최소 매칭이 되는데
이를 좀더 쉽게 푸는 것은 기본 버전인 POSIX BRE에는 존재하지 않는다. 그래서 기본버전에서 위와 같이 다소 어렵게 표현된 것이다.
그러나 특이하게도 vim에서는 POSIX BRE를 사용하지만 non-greedy 수량자인 \{-}를 제공한다.
- vim 에디터에
It's a gonna be <b>real</b>It's gonna <i>change everything</i> I feel를 작성 - 타이핑 후 /<.+> 으로 검색 (greedy matching>
- /<.{-}> 로 다시 검색 (non-greedy matching>
1
2
3
4
5
6
7
8
9
10
$ vim hi.txt
It's a gonna be <b>real</b>It's gonna <i>change everything</i> I feel
$ cat hi.txt
It's a gonna be <b>real</b>It's gonna <i>change everything</i> I feel
$ cat hi.txt | grep /<.\+>
$ cat hi.txt | grep /<.\{-}>
PCRE에서 사용하는 non-greedy matching 기능은 Lazy quantifier이라고 부르는데, ?를 더하면 된다.
즉
1
2
3
4
5
$ echo $var2 | grep -P -o "<.+?>"
<b>
</b>
<i>
</i>
여기서 -P는 PCRE에 대해서 실행한다는 것이다. 왜냐하면 lazy quantifier는 PCRE에서만 지원되서 POSIX REGEX모드에서는 사용할 수가 없다. 그래서 -P matcher를 붙여서 PCRE모드를 실행한 것이다.
/usr/share/dict/words라는 디렉토리에는 단어들이 많이 있다.
실습
1
2
3
4
5
6
7
8
9
10
11
12
$ var4='URLS : http://asdf.com/en/ , https://asdf.com/en/'
$ echo $var4 | grep --color 'http://[A-Za-z./]*'
http://asdf.com/en/
$ echo $var4 | grep -o 'http://[A-Za-z./]+'
$ echo $var4 | grep -o 'http://[A-Za-z./]\+'
http://asdf.com/en/
$ echo $var4 | egrep -o 'http://[A-Za-z./]+'
http://asdf.com/en/
ERE문자를 BRE에서 \ 없이 사용하면 실제 문자로 인식하게 되어 아무것도 출력되지 않았다.
위처럼 인식하게 만들기 위해 \를 추가했지만, grep 대신 egrep을 사용하면 \를 추가하지 않아도 된다.
실습2
curl : 터미널에서 웹 페이지를 접속하는 유틸 을 사용하여 url링크를 추출
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
$ curl -s https://www.naver.com | egrep -o 'https://[0-9a-zA-Z.]+/'
https://www.naver.com/
https://s.pstatic.net/
https://www.naver.com/
https://s.pstatic.net/
...
중복된 값 제거
$ curl -s https://www.naver.com | egrep -o 'https://[0-9a-zA-Z.]+/' | sort -u
https://book.naver.com/
https://business.naver.com/
https://campaign.naver.com/
https://comic.naver.com/
https://contents.premium.naver.com/
https://developers.naver.com/
https://dict.naver.com/
https://expert.naver.com/
https://finance.naver.com/
https://help.naver.com/
https://in.naver.com/
...
.대신 [^<>]를 사용한 이유는 greedy matching 성질 때문에 <<<>><><>> 처럼 제일 끝에 걸로 추출하기 위해
$ curl -s https://www.naver.com | egrep -o "<img [^<>]+>"
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAGAAAABgCAMAAADVRocKAAAC91BMVEUAAACE1dAbf6jE1Nq/z9e82drQ3OG7ytOzws+6x9QNs7MeLpQSx60QrLAfL50gMakTxKyzwc8fMacSr6yywc8fMKIdLYzJ1d4KrrW6ydMJrrUbr6QgMKW2xNEcr6W7ydUfL5cIr7XBztgMtbMeL50fMaQQzrI0tK4cLIQUvq
...
PCRE에서의 non-greedy matching인 ? 사용
$ curl -s https://www.naver.com | grep -P -o "<img .+?>"
<img src="https://s.pstatic.net/dthumb.phinf/?src=%22https%3A%2F%2Fsports-phinf.pstatic.net%2F20220225_38%2F1645792775360TpuI0_JPEG%2F15_20220225018F202.jpg%22&type=nf728_360" data-src="https://s.pstatic.net/dthumb.phinf/?src=%22https%3A%2F%2Fsports-phinf.pstatic.net%2F20220225_38%2F1645792775360TpuI0_JPEG%2F15_20220225018F202.jpg%22&type=nf728_360" alt="'풀세트 대역전승' 현대건설에 시즌 첫 연패를 안겨준 KGC인삼공사"
BRE vs ERE - BRE 사용하는 유틸 : grep, vim, sed … - ERE 사용하는 유틸 : egrep, awk - PCRE는 별개지만 기본적으로 ERE를 베이스로 함
back - reference
소괄호 () : back-reference, group
매칭된 결과를 다시 사용하는 패턴이다. ()로 묶인 패턴 매칭 부분을 “#”의 형태로 재사용
etc/passwd 라는 곳은 유저의 정보를 담은 곳으로 총 7개로 구분되어 있다. 구분자는 :이다
username:x:(패스워드였지만 지금은 안씀):uid:gid:정보(생략가능): 홈디렉토리 : shell
이 때, 홈디렉토리와 username이 같은 경우를 일반유저라고 한다. 유저명이 달라질 때마다 홈디렉토리도 달라진다.
1
2
$ egrep "^(.+):x:[0-9]+:[0-9]+:.*:/home/\1:" /etc/passwd
jaehoyoon:x:1000:1000:jaehoyoon,,,:/home/jaehoyoon:/bin/bash
앞에 (.+)는 username을 찾는 것이고, \1 이라는 것은 앞에 불러온 매칭인 (.+)에 대한 결과값을 저장하는 것이다. 즉 (.+)을 통해 jaehoyoon이 매칭되었다면 \1도 jaehoyoon이 매칭된다.
이 때 괄호가 1개였기에 \1이고, 두개 세개가 쓰인다면 \2,\3 이 된다.
이것을 활용하여 태그와 태그안에 적힌 부분을 함께 추출할 수 있다.
1
2
3
$ echo $var2 | egrep -o '<([a-zA-Z0-9]+)>.*</\1>'
<b>real</b>
<i>change everthing</i>
()를 통해 \1 과 매칭해준 것이다.
alternation
| or에 해당하는 것으로 (cat | dog) 이면 cat 또는 dog 를 추출, 주의할 것은 대/소문자를 가려서 걸러낸다. |
1
2
3
$ echo "cat and dog" | egrep -o "(cat|dog)"
cat
dog
실습
1
2
3
4
5
6
7
8
9
10
11
$ curl -s https://www.naver.com | egrep -o "<(a|A) [^<>]+>.+</\1>"
$ curl -s https://www.naver.com | grep -o "<\(a\|A\) [^<>]\+>.\+</\1>"
<a href="#newsstand"><span>뉴스스탠드 바로가기</span></a>
<a href="#themecast"><span>주제별캐스트 바로가기</span></a>
<a href="#timesquare"><span>타임스퀘어 바로가기</span></a>
<a href="#shopcast"><span>쇼핑캐스트 바로가기</span></a>
<a href="#account"><span>로그인 바로가기</span></a>
...
$ curl -s https://www.naver.com | egrep -o 'http://[0-9A-Za-z./_]+\.(jpg|JPG|png|PNG)'
| ?,+,{},(), | 다 ERE 문법이므로 escape 시켜줘야 한다. |
대문자도 신경써야 할 것이고, 여기서 .는 진짜 . 을 검색해야 하기 때문에 escape 시킨 것
substitution
교체하는 것은 sed, awk을 많이 사용한다.
- sed
1
2
3
4
5
$ echo $var2 | sed -e "s/<[^<>]\+>/ /g"
It`s gonna be real It`s gonna change everthing I feel
$ echo $var2 | sed -re "s,<[^<>]+>, ,g"
It`s gonna be real It`s gonna change everthing I feel
sed는 구분자로 /를 많이 쓰지만, , 도 쓰기도 한다. 기본적으로 작성할 때는 BRE로 쓰지만, ERE로 바꿔서 사용할 줄도 알아야 한다.
- awk
1
2
$ echo $var2 | awk '{ gsub(/[ ] *<[^<>]+>[ ]*/, " "); print }'
It`s gonna be real</b>It`s gonna change everthing</i> I feel
awk 는 ERE를 사용해서 \를 붙이지 않았다.
실습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
$ curl -s https://www.naver.com | sed -n "s,<\(a\|A\) [^<>]\+>\(.\+\)</\1>,\2,gp"
<div>[지금 우크라 국경에선] "피란길 아이들 울음 끊이지 않았다"</div>
<div>한국리서치 "李·尹 39.8% 동률"…D-10 오차범위내 초접전</div>
<div>이재명 "선거때 누구 눌러 포기압박 안돼…통합정부로 정치교체"</div>
<div>尹, 단일화 전말 작심 공개…安책임론 부각·지지층 결집 승부수</div>
<div>安측 "尹측 진의 확인하려 만나…전권협상 대리인 아니었다"</div>
<div>북, 5년만에 사거리 2천㎞ 안팎 미사일 쏜듯…주일미군 사정권</div>
<div>靑, L-SAM·'한국형 아이언돔' 시험발사 성공 공식확인</div>
<div>與 "불기소 처분 은행, 尹처가에 대출"…野 "엉뚱한 추정"</div>
...
$ curl -s https://www.naver.com | sed -rn "s,<(a|A) [^<>]+>(.+)</\1>,\2,gp"
<span class="opt_item">도움말</span>
<span class="opt_item">신고</span>
자동완성 끄기
<i class="ico_mail"></i>메일
<li class="nav_item">카페</li>
<li class="nav_item">블로그</li>
<li class="nav_item">지식iN</li>
<li class="nav_item"><span class="blind">쇼핑</span></li>
<li class="nav_item">Pay</li>
...
Boundary
- \b : boundary가 맞는 표현식만 찾는다. 즉 단어 경계면을 기준으로 검색
- \B : boundary에 맞지 않는 표현식만 찾는다. 즉, 단어 경계면이 아닌 경우에만 검색
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
$ var5='abc? <def> 123hijklm'
$ echo $var5 | egrep -o "[a-j]+"
abc
def
hij
$ echo $var5 | egrep -o "\b[a-j]+\b"
abc
def
$ echo $var5 | egrep -o "\B[a-j]+\B"
b
e
hij
+ predefined character class
이미 정의해놓은 클래스
| 클래스 | 설명 | set |
|---|---|---|
| [[:cntrl:]] | 제어문자들을 의미 | [\x00-\x1f\x7f] |
| [[:punct:]] | 출력 가능한 특수문자들 | [!-/:-@[-`{-~] |
| [[:space:]] | white space (공백으로 사용되는 6개의 문자 | [ \t\r\n\v\f] |
| [[:print:]] | 출력 가능한 문자들 | [ -~] |
| [[:graph:]] | 공백을 제외한 출력 가능한 문자들 | [!-~] |
\x##는 hex code 표현으로 PCRE에서만 지원
1
2
3
4
5
6
7
8
9
10
$ var5="sunyzero@email.com:010-8500-80**:Sun-young Kim:AB-0105R"
$ echo $var5 | egrep -o "^[[:alpha:]@]+"
sunyzero@email
$ echo $var5 | egrep -o "^[[:alpha:]@]+\.[a-z]+"
sunyzero@email.com
$ echo $var5 | egrep -o "[[:upper:][:digit:]-]{8}"
010-8500
AB-0105R
POSIX REGEX and PCRE
- POSIX REGEX
- 간단한 패턴 매칭에 사용
- 복잡해지면 성능저하
- PCRE
- 확장된 정규표현식
- 매우 빠른 속도, 확장된 표현식
- C, C++, 기타 대부분의 언어가 지원
- 실무라면 PCRE를 사용
1
2
3
4
5
6
7
$ ipv4="123.456.12.1 12.467.56.5 323.666.893.12 111.11.11.1 \
>1123123.123123123.123123.123123123"
$ echo $ipv4 | egrep --color "([0-9]|[0-9][0-9]|[0-1][0-9][0-9]|2[0-5][0-5])\. \
>([0-9]|[0-9][0-9]|[0-1][0-9][0-9]|2[0-5][0-5])\. \([0-9]|[0-9][0-9]|[0-1][0-9][0-9] \
|2[0-5][0-5])\.([0-9]|[0-9][0-9]|[0-1][0-9][0-9]|2[0-5][0-5])"
123.456.12.1 12.467.56.5 323.666.893.12 111.11.11.1 1123123.123123123.123123.123123123
한글찾기
1
2
3
4
5
$ egrep --color '한.' hangul-utf8.txt
한글은 한국어에서 사용되는 문자이다. 여기 UTF8로 인코딩된 한글과 한자가 보이는가?
$ egrep --color '[ㄱ-ㅎ|ㅏ-ㅣ|가-힣]+' hangul-utf8.txt
한글은 한국어에서 사용되는 문자이다. 여기 UTF8로 인코딩된 한글과 한자가 보이는가?
REGEX 테스터기 사이트
- https://regexr.com/
- https://www.regextester.com/
- https://regex101.com/
Glob
unix혹은 linux 명령행에서 파일명 패턴에 쓰이는 문자열
regex와 비슷하지만 regex는 아니다.
glob 테스터 사이트
- http://www.globtester.com/
backtracking
greedy matching 속성으로 인해 역탐색을 하는 행위, 이로 인해 성능이 많이 저하되기도 한다.
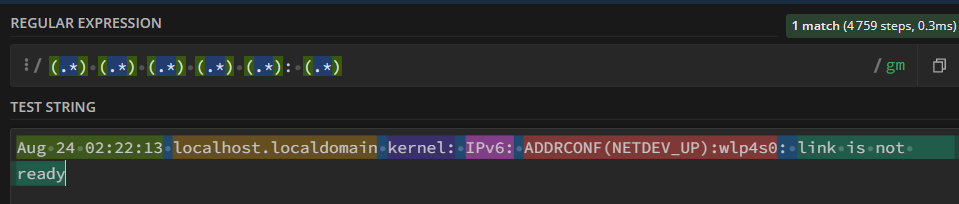
4759번 검사했다는 것을 보여준다. 그래서 greedy한 표현식을 바꾸기 위해 .을 다르게 바꿔보았다.

3개만 바꿔도 257로 줄어드는 것을 볼 수 있다.
그래서 backtracking을 줄이는 연습을 많이 해야 한다. . 대신에 []* []+ 등을 많이 쓴다. 공백 문자도 계속 확장하게 만드는 요인이므로 되도록 사용 안하는 것이 좋다.
summary
- backtracking을 피하려면
- .* 혹은 .+ 과 같이 greedy한 표현식을 남발하지 않는다. 특히 .은 되도록 쓰지 않는게 좋다. 쓴다면 lazy quantifier를 사용하는 것이 좋다.
- 공백을 반복할 수 있는 표현식은 피한다.
- backtracking으로 손실되는 성능은
- 복잡도에 따라 다르지만, 일반적으로 non greedy한 표현식보다 100~1000%의 성능 하락
