
Data Labeling
labeling이란 확보한 원시 데이터(raw data)를 학습에 사용하기 위해 데이터를 만드는 작업을 말한다. 레이블링(Labeling) 또는 어노테이션(Annotation), 태깅(Tagging)이라 부른다. Computer vision에서는 주로 이미지에 필요한 태스크(classification, detection,..)에 대해 결과를 미리 입력하는 작업이다. 분류의 경우는 이미지에 해당하는 클래스 정보를 입력하고, detection에 경우 이미지에 대상 객체의 bbox와 클래스 정보를 입력해야 한다.
데이터를 잘못 만드는 경우 결과는 당연히 좋지 않을 것이다. 그래서 데이터 레이블링을 하는 툴을 하나 정도는 다룰 줄 아는 것이 중요하다. 데이터를 만들어야 하는 상황은 가지고 있는 데이터셋과는 다른 환경과 조건에 대한 데이터도 함께 학습을 시키고 싶다면, 자신이 얻은 데이터셋을 직접 레이블링해서 추가할수도 있다. 또는 가상환경에서의 데이터와 현실환경에서의 데이터를 융합해서 데이터 증강을 통해 학습을 시킬수도 있을 것이다.
데이터를 다루는 작업이 필요한 이유는 데이터의 개수는 한계적인데, 모델의 성능은 데이터의 수가 많을수록 올라간다. 실제로 2~3TB의 데이터를 직접 제작하기도 하기 때문에 중요한 작업이다.
Data labeling Tool
이미지 데이터를 레이블링하는 툴은 CVAT, labelme, labelImg 등 많이 있다.
CVAT
CVAT는 Docker Image를 제공하여 편리하게 설치할 수 있다.
WSL 설치
window에 wsl2를 설치하면 윈도우 커널에서 linux 환경을 사용할 수 있다. 이를 설치하면 대체로 linux 커널을 자주 바꿔줄 필요가 없어진다. 실제 자율주행과 동일한 임베디드 환경을 사용하거나 멀티 카메라를 받아서 사용할 때는 리눅스를 써야할 수 있지만, 이를 제외하고는 wsl2가 편리하다. wsl2에서는 GPU Device를 linux 커널에서 사용할 수 있어서 window환경에서 linux/ubuntu 기반의 tensorflow, pytorch, cuda 등 다양한 환경을 구성할 수 있다.
wsl1에서는 gpu를 사용하기 어려웠고, linux에서의 opencv에서 show를 하기 복잡했다. 그러나 wsl2로 넘어오면서 바로 사용이 가능해졌다.
wsl 설치 홈페이지 : https://docs.microsoft.com/en-us/windows/wsl/install
설치 전 윈도우 버전을 반드시 확인해야 한다.
위의 홈페이지로 들어가면 WSL 설치 과정이 나와있고, 1과 2가 통합되면서 설치가 간단해졌다.
- wsl 패키지 설치
관리자 권한으로 powershell 이나 cmd를 실행하여 wsl 기능을 설치한다.
1
wsl --install
- ubuntu 배포판 설치
microsoft store에서 ubuntu 20.04나 18.04를 설치한다. 여기서 LTS는 lone term support 라고 해서 장기간에 걸쳐 지원하도록 만든 소프트웨어 버전이다. 가장 최신버전인 22.04도 지원하고 있다.
20.04 까지는 systemd를 사용할 수 없지만, 22.04부터는 systemd를 사용할 수 있다고 한다.
설치가 끝나고 실행하면 계정을 설정하라고 나온다. 자신이 사용할 계정을 설정해주면 된다. 이 프로그램은 ubuntu와 동일하기 때문에 gcc나 ubuntu에서 사용 가능한 명령어들을 사용할 수 있다.
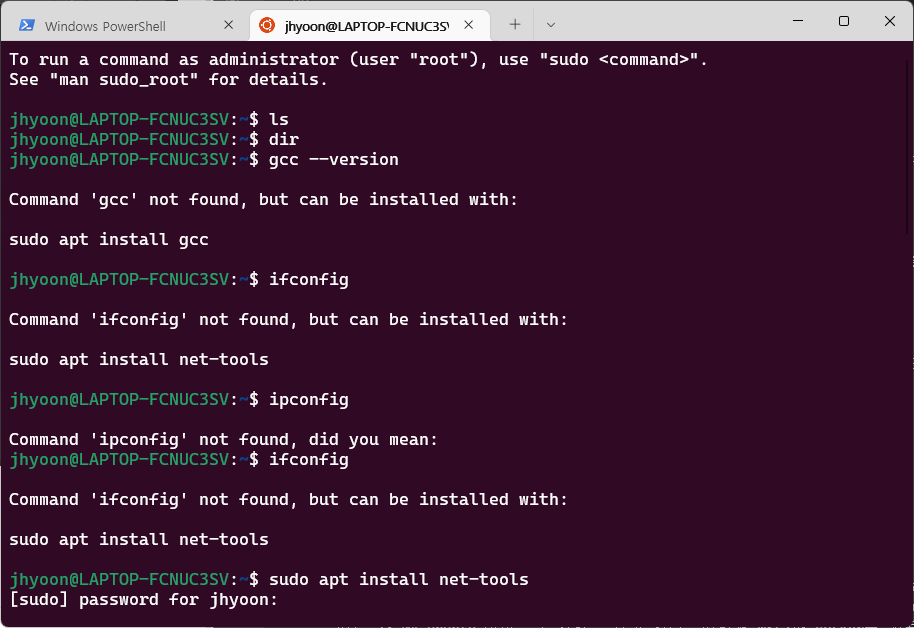
설정한 계정이름은 매 줄마다 표시되는 이름이자 이 os의 계정 이름이다. 그리고 비밀번호는 재설정이 불가능하기 때문에 까먹는다면 ubuntu를 재설치해야 하므로 신중히 생성하도록 한다.
docker
최신 노트북들이 20.04 ubuntu버전이 아닌 18.04를 하면 네트워크가 잘 안잡히거나 소리가 안나는 문제들이 많다. 그래서 메인 os는 20.04로 하되 docker로 18.04 컨테이너를 만들면 따로 18.04 ubuntu 버전을 설치할 필요가 없다. 따라서 WSL2와 docker를 사용하는데 익숙해지면 환경을 구축하는데 드는 비용이 감소하고, 다른 사람들에게도 손쉽게 실행 가능한 환경을 구축할 수 있다.
docker를 사용할 때 window에서는 docker desktop을 사용할 수 있지만, linux의 경우는 cli에서만 사용이 가능하다.
docker desktop을 다 다운 받았다면 다음 화면이 나올 것이다.
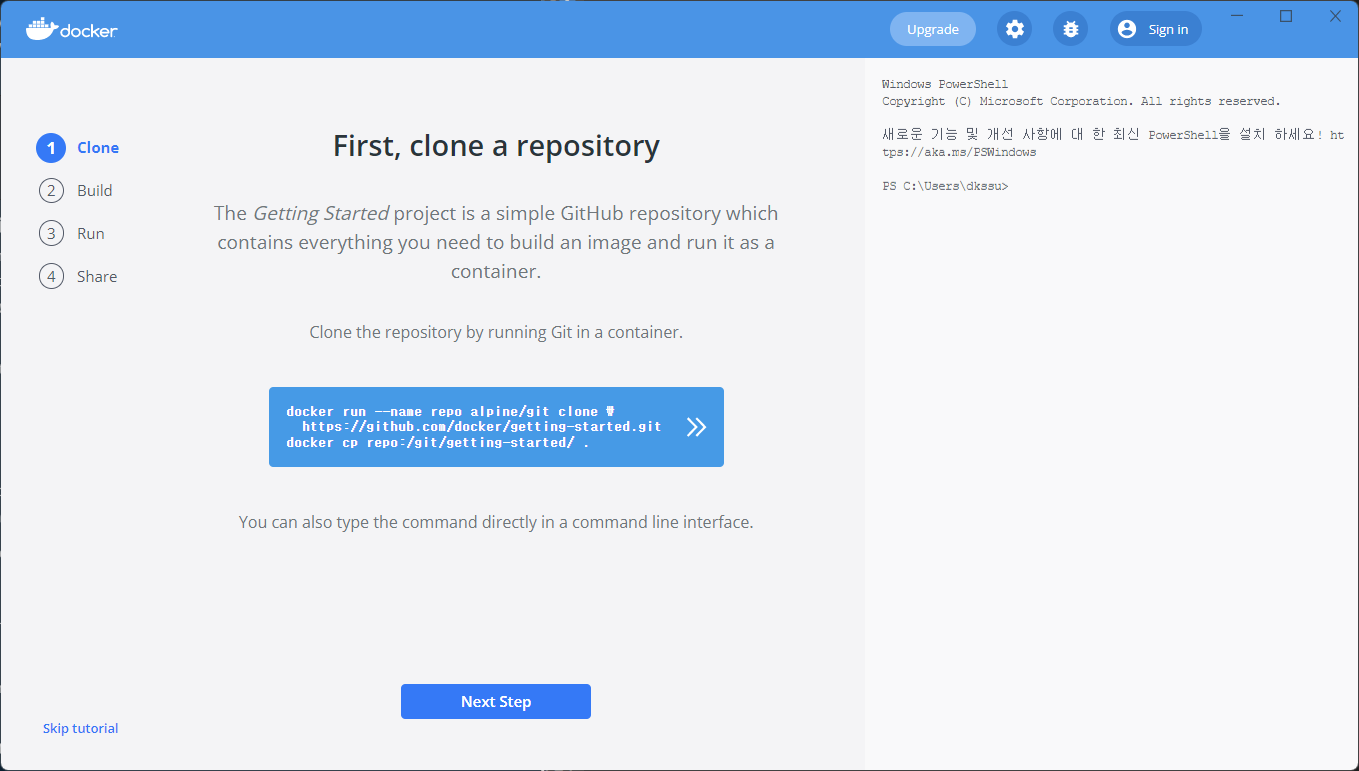
이는 튜토리얼이므로 스킵을 해도 되고 따라가도 된다. git clone을 할 경우는 오른쪽의 command를 통해 CVAT을 설치한다. 그러나 어차피 튜토리얼이 종료되면 다시 up을 해야하므로 스킵해서 하는 것이 좋다.
스킵을 하거나 튜토리얼을 끝내고 나면, 아래와 같은 화면이 뜬다.
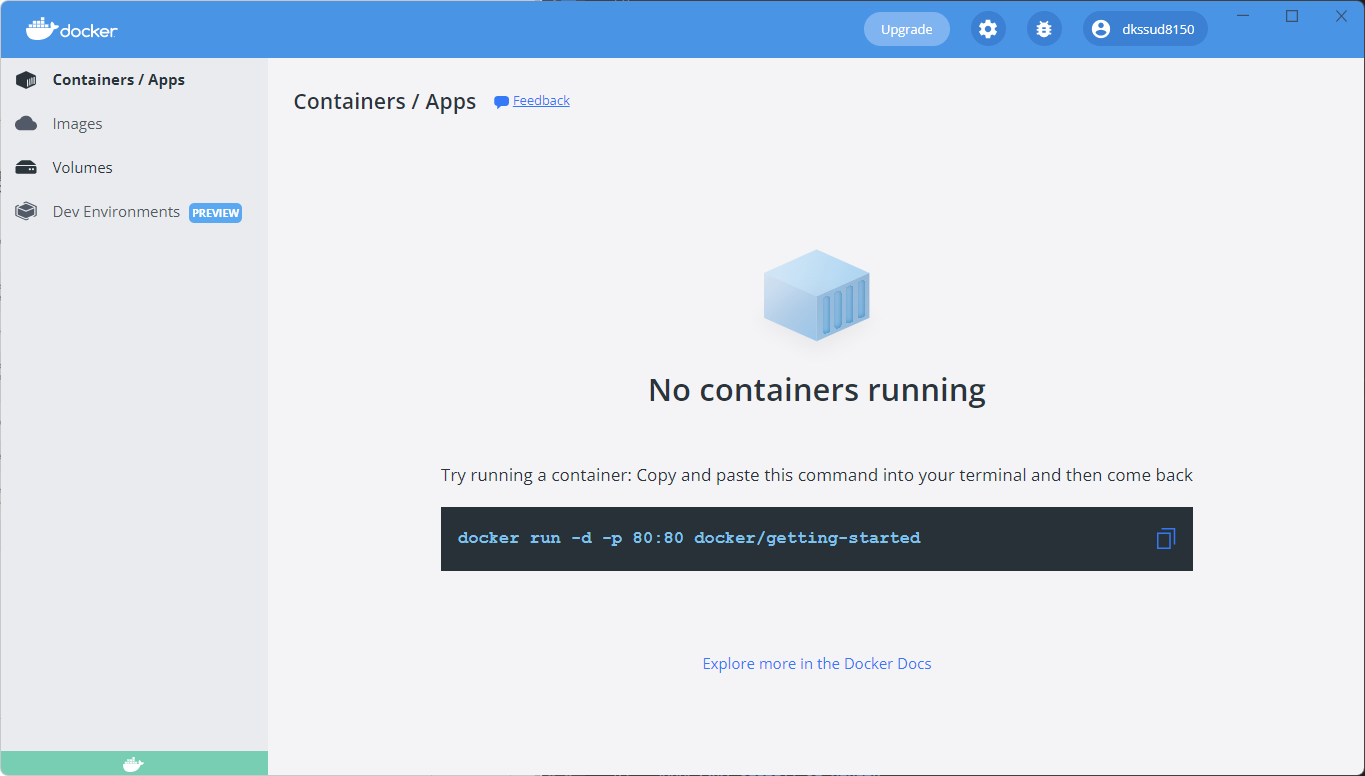
여기서 cmd를 하나 켜서 작업할 폴더에 들어간 후 화면에 보이는 코드를 복사하여 그대로 붙여넣는다.
1
docker run -d -p 80:80 docker/getting-started
-p는 port를 뜻한다. 이를 치면 image가 없다고 뜨면서 설치하게 된다. 설치가 완료되면, 다음 코드를 친다.
CVAT install in Window
원래는 window에서 docker를 사용하면 docker가 window를 참조하게 되어 있지만, window에서 wsl을 사용하는 곳에 docker를 올리게 되면, docker가 linux(wsl)을 참조하게 된다. 그래서 window + wsl + docker를 사용할 때는 window → wsl → docker 순으로 올려진다.
1
2
3
4
git clone https://github.com/opencv/cvat
cd cvat
docker-compose up -d
뒤의 -d는 daemon을 뜻하는 것으로 background process로 동작을 시키겠다는 의미이다. linux를 사용하다보면 daemon이 되게 많이 등장한다.
설치가 완료되면 아래와 같이 CVAT에 대한 컨테이너가 생성된다.
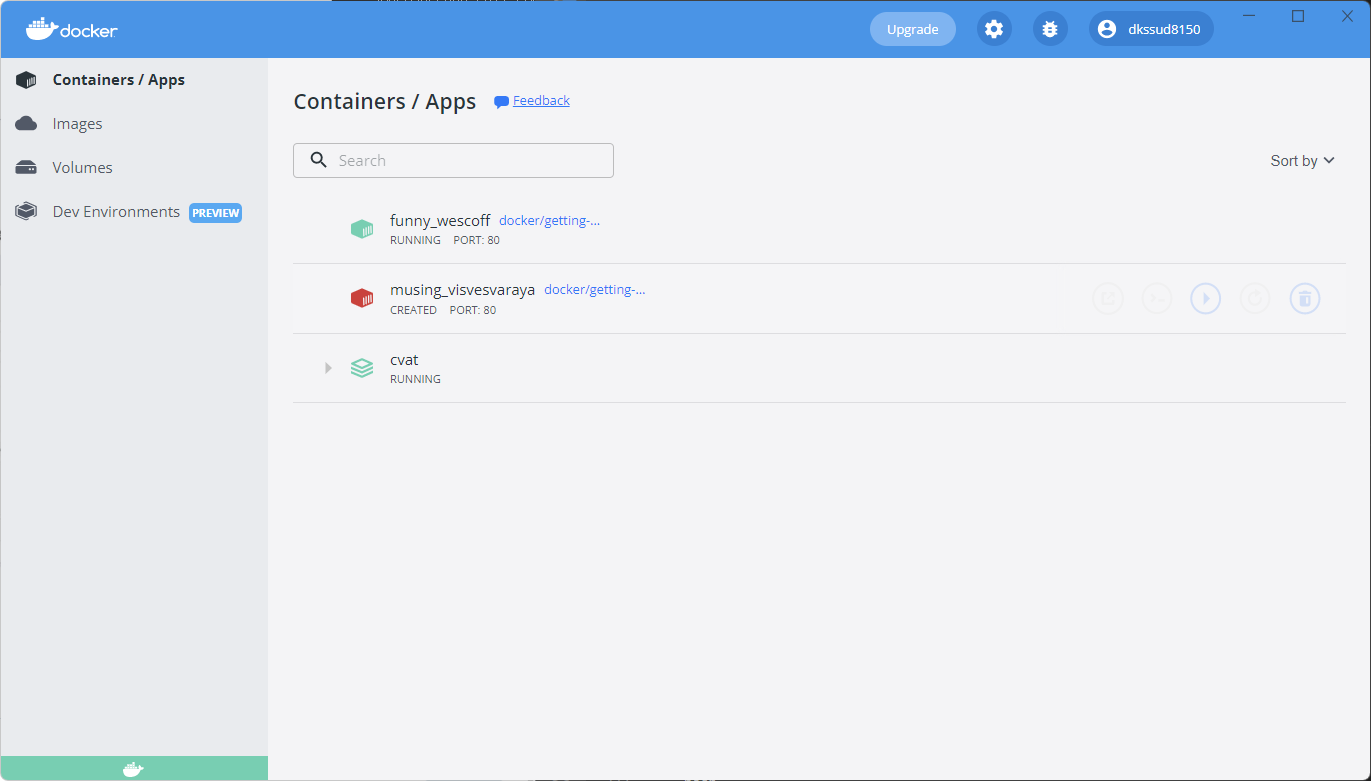
CVAT install in Ubuntu
위의 과정은 window에서의 CVAT 설치 방법이었고, 이제는 ubuntu에서 CVAT을 설치하는 방법을 소개한다.
설치에 대한 설명 사이트는 https://docs.docker.com/engine/install/ubuntu/ 이고, docker desktop과 달리 linux는 CLI 환경에서 설치해야 한다.
docker를 사용할 때 권한 문제가 발생할 수 있다. 이 때는 sudo su-를 사용하는 것보다 유저 그룹에 docker를 추가하면 편리하게 사용이 가능하다.
1
2
$ sudo groupadd docker
$ sudo usermod -aG docker $USER
그룹에 docker를 추가하고, user 그룹에 docker 그룹을 추가하는 코드이다.
그 후 docker-compose 패키지를 설치하고, CVAT 레포지토리를 불러온다.
1
2
3
4
5
$ sudo apt --no-install-recommands install -y python3-pip python3-setuptools
$ sudo python3 -m pip install setuptools docker-compose
$ sudo apt --no-install-recommands install -y git
$ git clone https://github.com/opencv/cvat
$ cd cvat
그 후 CVAT을 공용 컴퓨터에 넣고, 다수의 사람들이 접근을 해서 사용할수 있는데, 이 때 HOST를 설정해줘야 하므로 아래의 코드를 설정해줘야 한다.
1
2
$ ifconfig
$ export CVAT_HOST=my-ip-address
윈도우에서 ip주소를 확인할 때는 ipconfig이다.
1
$ docker-compose up -d
CVAT create account
window 또는 ubuntu에서 모든 설치가 끝나고 나서 만약 CVAT_HOST를 설정하지 않았다면 다음 주소를 입력해서 들어가야 한다. http://localhost:8080/auth/login
CVAT_HOST를 설정했다면, http://{IP address}:PORT/auth/login 를 통해 공용 컴퓨터로 접속이 가능하고, 위의 화면에서 각자의 계정이 존재해야 하므로 계정을 생성한다. 누가 어떤 작업을 하는지 다른 사람이 볼 수 있어야 겹치는 일이 없다.
이 화면은 메인 페이지이고, CVAT의 작업 단위는 3단계로 구성되어 있다. 가장 큰 단위는 Projects 이고, 그 밑에 여러 개의 task가 존재한다. task에는 classification task, detection task, segmentation task 등이 존재할 것이고, 그 밑에 Job이라는 이미지 단위가 존재한다. 만약 한 task가 1만장을 10명에서 진행한다고 가정할 때, 하나의 task로 작업하다가 task가 날아가거나 삭제되면 모든 작업이 리셋되는 것이므로, 특정 N개의 이미지를 기준으로 job 단위로 나누어 작업을 수행한다.
CVAT make Task
메인 화면에서 프로젝트를 생성해도 되고, task를 새로 생성해도 되는데, 현재는 task만 생성해볼 것이다. +를 눌러 create a new task를 클릭한다.
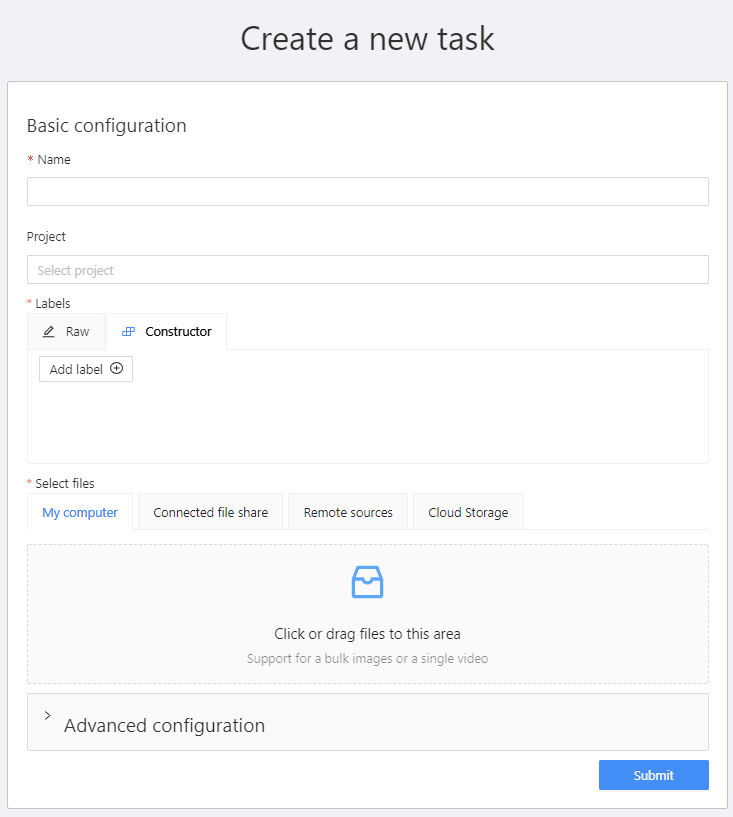
그러면 이렇게 화면이 하나 뜬다.
- Name : task의 이름
- Project : 연결시킬 project 이름
- labels : 원하는 클래스를 원하는 색상으로 추가하는 기능이고, 이는 포함되어 있는 job들이 이 label을 공유하기 때문에 잘 정의해줘야 한다.
- select files : labeling할 이미지를 직접 업로드하는 기능이다.
- advanced configuration : 상세옵션으로, 이미지 퀄리티나 태스크, job의 개수 등을 지정할 수 있는 기능이다.
생성하고 나면 생성 시 설정한 이미지 개수로 자동 구성되고, 어느 정도 진행이 되고 있는지 확인할 수 있다.
CVAT은 labeling 한 데이터를 배포할 때 kitti, bdd100k, cityscape, yolo 등 다양한 포맷의 데이터로 변환이 가능하다.
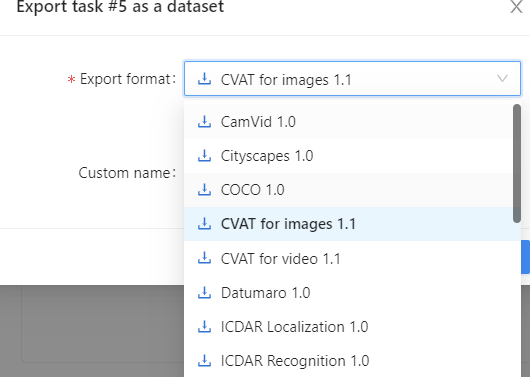
CVAT make Project
상단의 탭에서 project를 누른 후 + -> create new project 를 클릭한다.
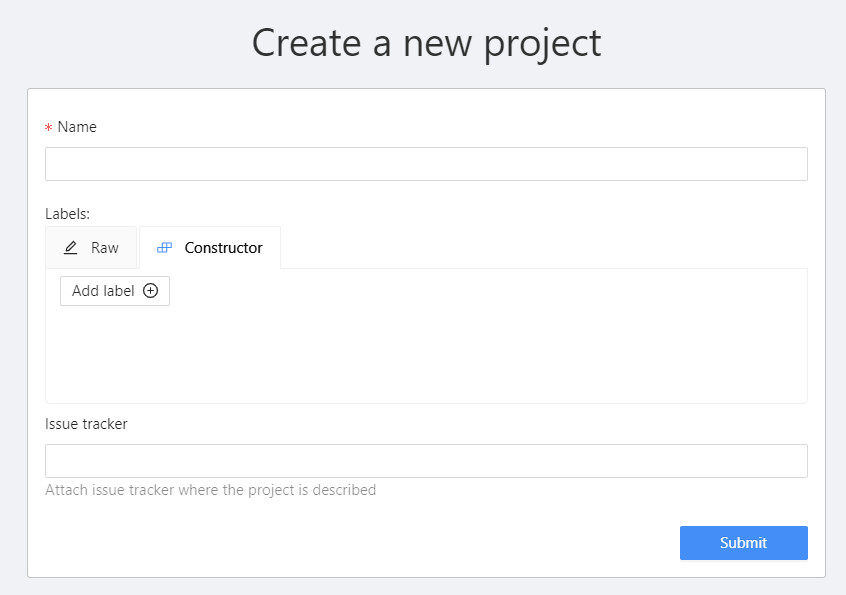
이름과 label을 지정해준 후 submit한 후 open projects를 누르게 되면 생성된 project를 확인할 수 있다.
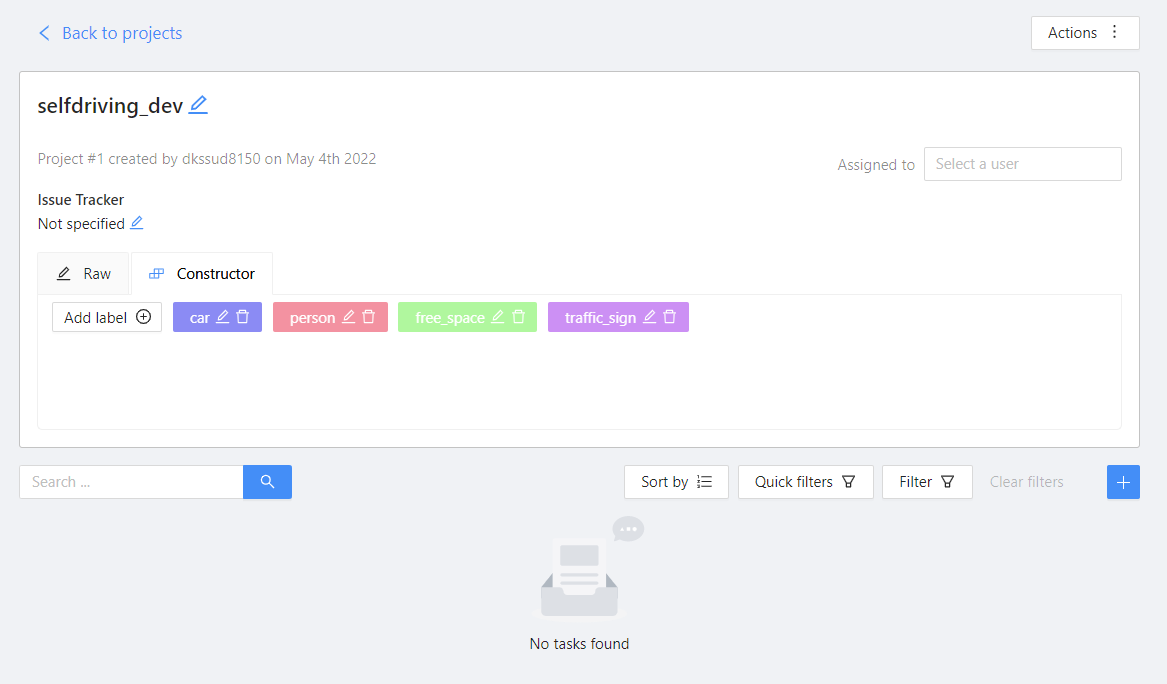
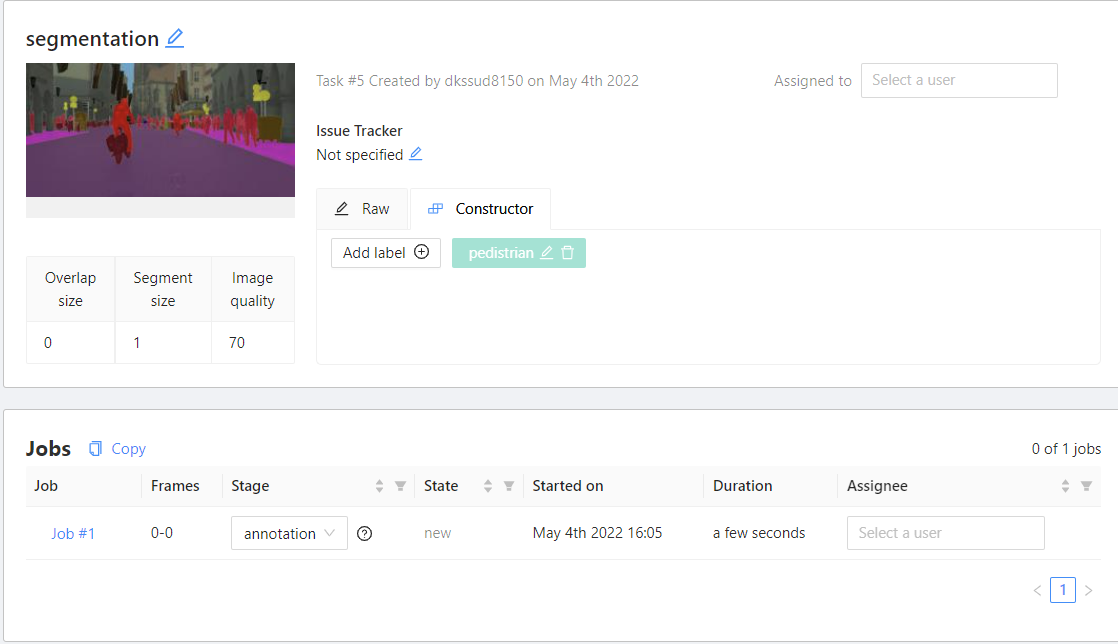
현재는 task가 없으므로 하단에 +를 눌러 task를 생성한다. 이름을 지정해주고, advanced configuration에서 image quality를 보면 현재는 70%이다. 그 이유는 원본 그대로를 올리게 되면 부담이 될 수 있기 때문이다. 그러나 우리는 이미지를 아주 작게 진행할 것이므로 100으로 지정해주고, job을 구분할 때 사용하는 segment size를 2로 한다. 2로 주게 되면 이미지 개수를 2로 하여 job을 구분한다.
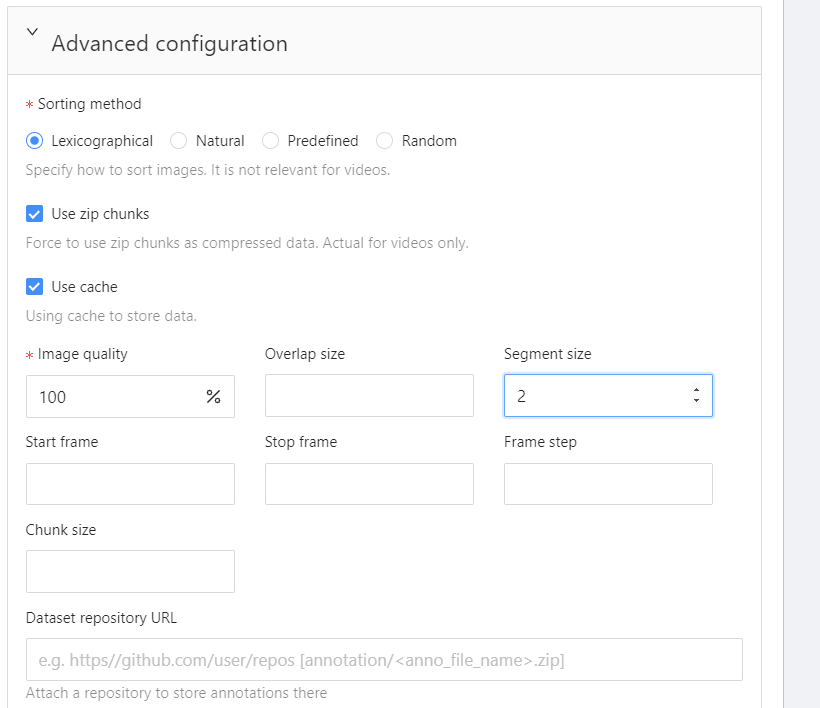
이미지를 업로드한 후 submit한다.
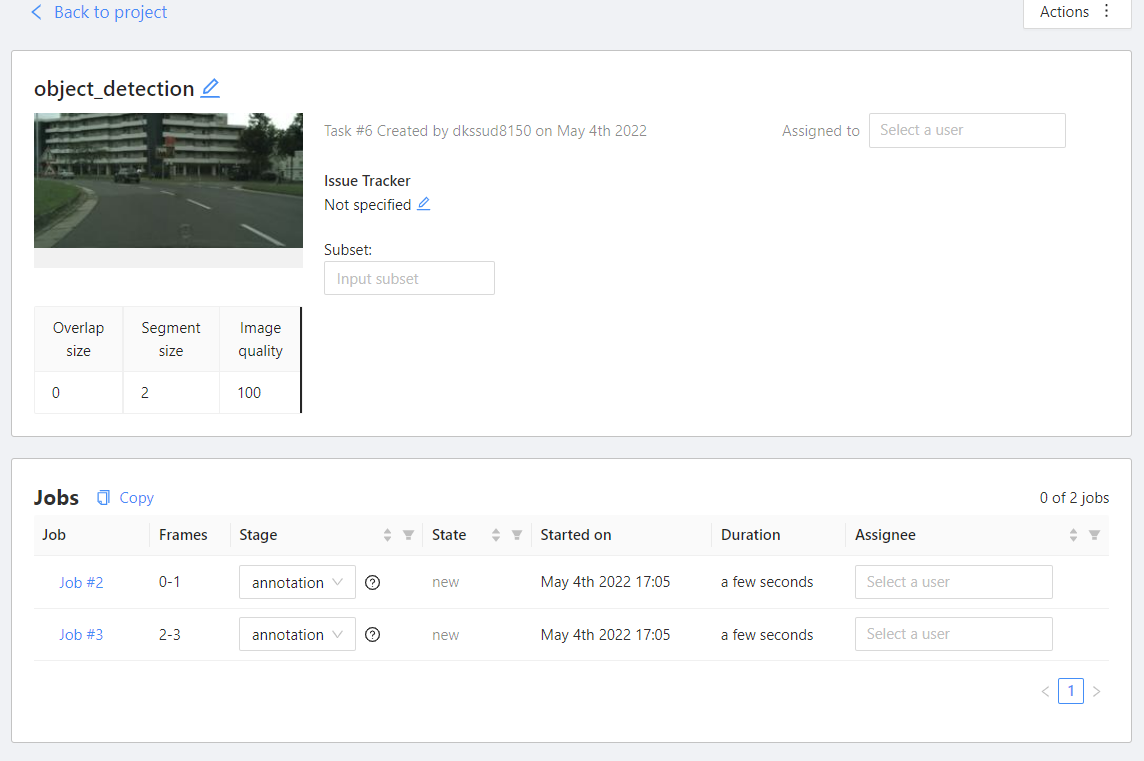
동일한 방식으로 task를 하나 더 생성한다.
object detection을 먼저 진행해보자. task에서 open을 누르고, 첫번째 job을 클릭한다.
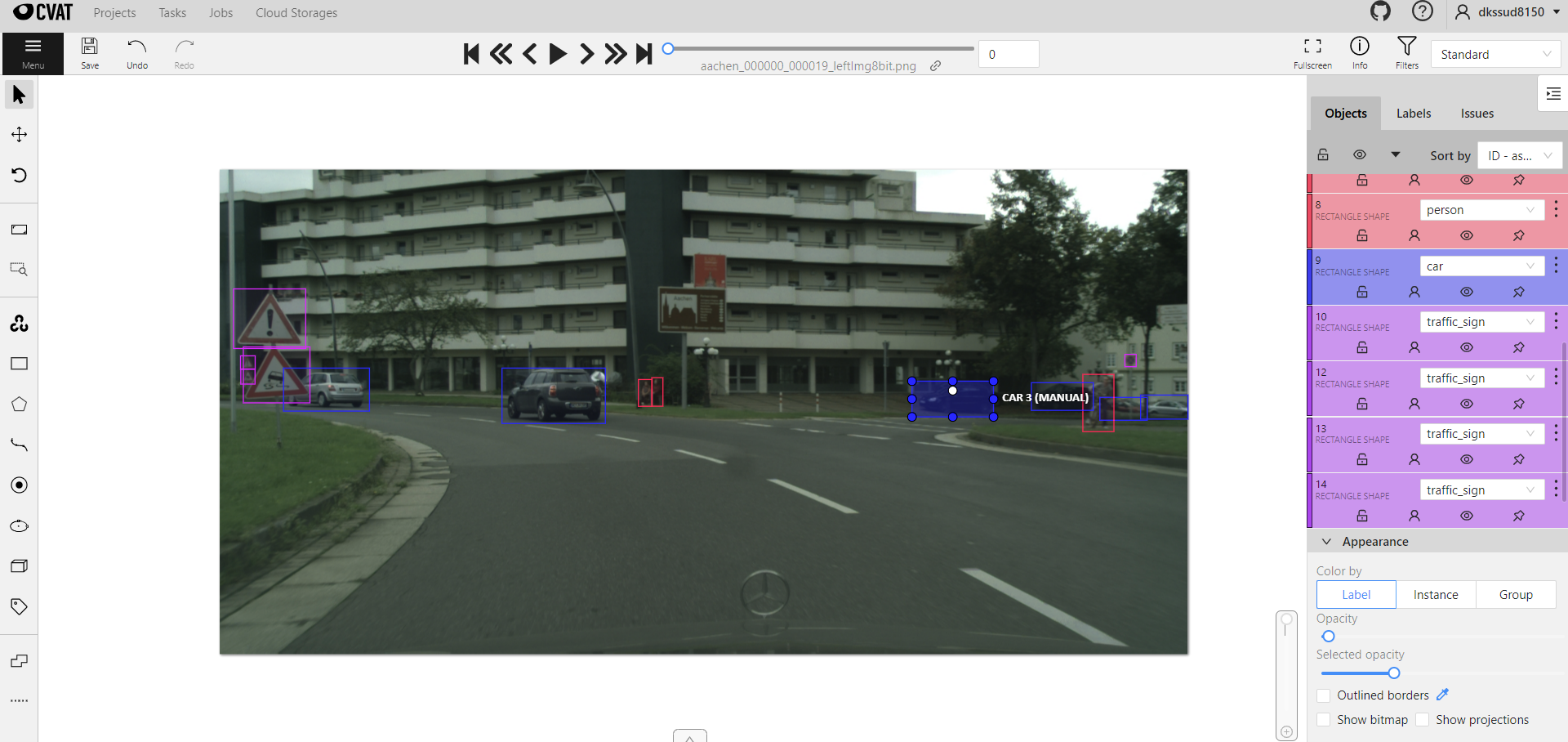
이와 같이 직접 레이블링이 가능하다. 좌측에 사각형 모양 위에 마우스 커서를 가져가면 class를 지정해줄 수 있고, share을 클릭하면 사각형을 그릴 수 있게 된다. 객체에 맞게 그려주고, N키를 누르면 다시 사각형 그리기가 가능하다. 그려진 박스에 우클릭하면 클래스를 변경해줄 수 있고, 우측 하단에 appearance에 보면 opacity, 즉 사각형의 투명도를 의미하고, 그 밑에 selected opacity는 마우스 커서를 박스 위로 가져갔을 때의 투명도를 의미한다. 상단에 >를 누르거나 F키를 누르면 다음 이미지로 가고, <를 누르거나 G키를 누르면 이전 이미지로 이동이 가능하다.
완료한 후 save를 누르고, export task에서 label format을 지정해준다. 그 후 상단의 task로 이동하고, object detection task를 open해보면 방금 작업했던 job의 state가 in progress라고 되어 있다. 이는 아직 우리가 끝내고 나오지 않았기 때문이다.
다시 job을 들어가서 finish the job을 클릭해준다.
그러면 job이 completed되었다고 나온다.
또는 finish the job 위에 change job state가 있다. 이를 통해 현재 상태를 변경해줄 수 있다.
추가적으로 review모드를 통해 잘못된 레이블링은 잘못되었다고 설정해줄 수 있다.
tasks 탭으로 이동하여 보게 되면 얼마나 진행되었는지 확인이 가능하다.

이제 sementation을 진행해보자. segmentation의 경우 1픽셀에 대한 값들을 레이블링해야 하므로 매우 정교해야 한다. 이 때는 사각형 밑에 polygon을 사용하여 점을 일일이 다 찍어줘야 한다. free space 즉 이동 가능한 공간을 칠해준다.
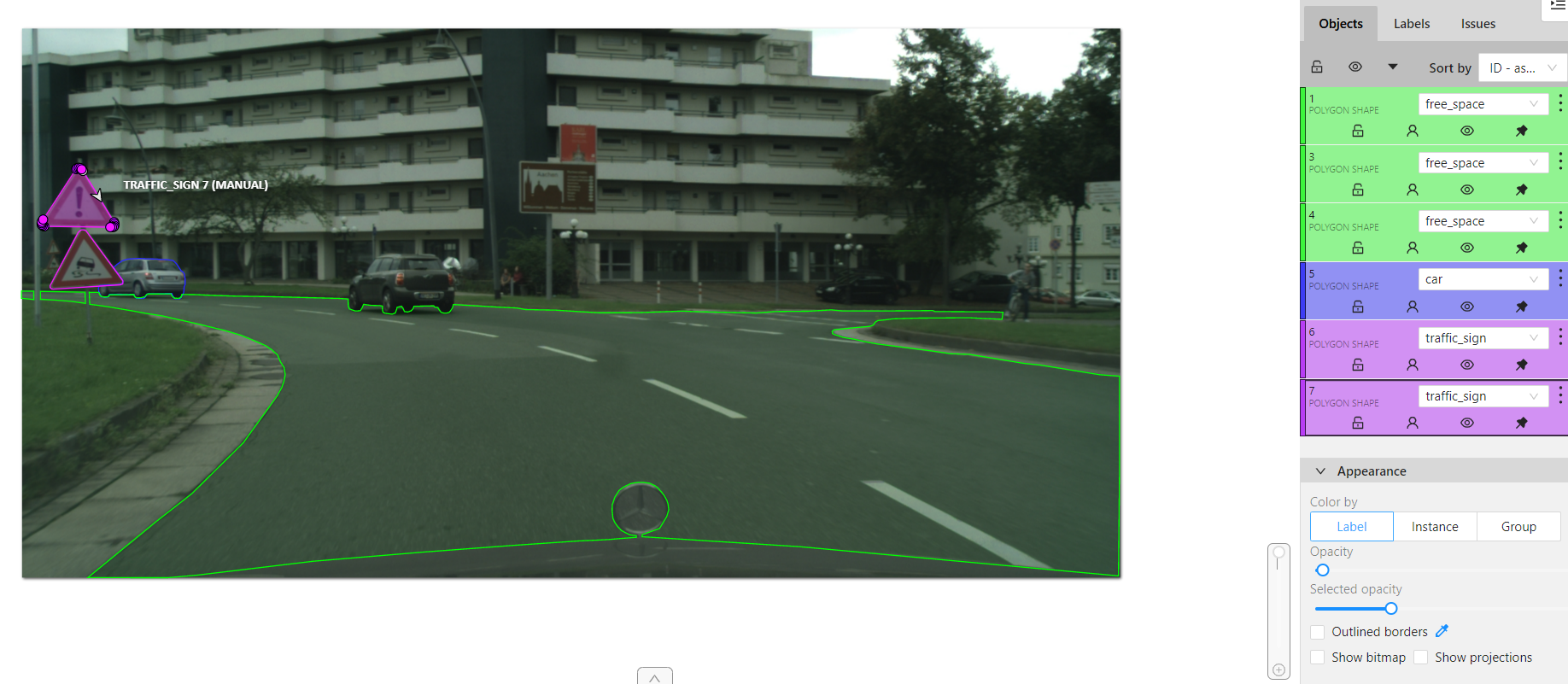
alt키를 누르면서 점을 클릭하면 삭제, shift키를 누르면서 점을 클릭하면 추가 점인데, 이것은 계속 누르고 있으면 연속적인 점을 찍게 되므로 조심히 클릭한 후 마우스 좌클릭으로 점을 찍어줘야 한다. 점을 드래그하면 점을 이동시킬 수 있다.
cvat에서는 이미지 밖에 좌표를 찍어도 이미지 안으로 옮겨진다.
cityscape format으로 추출한 뒤 colo.png를 보게 되면 다음과 같이 생성된 것을 볼 수 있다.

Data Augmentation
색상, 기하학적 형태 등을 변형하는 것을 data augmentation이라 하는데, 객체에 대해서는 색상을 변형해도 문제가 되지 않을 수 있으나, 신호등에 대해 색상을 변형한다면 정보가 틀려지게 되는 것이므로 문제가 발생할 수 있다.
augmentation에 사용되는 라이브러리는 imgaug(https://github.com/aleju/imgaug), albumentations(https://albumentations.ai) 등이 있지만, 대표적으로 이 두가지를 많이 사용한다. albumentations가 조금 더 전문적인데, pytorch와 잘 연동이 되어 있어 pytorch를 사용한다면 후자를 사용하는 것을 추천한다.
이 글에서는 albumentations를 사용할 것이고, imgaug에 대해서는 지난 블로그를 참고하는 것이 좋을 것 같다.
Albumentations 설치
github : https://github.com/albumentations-team/albumentations documentation : https://albumentations.ai/docs/
1
pip install -U albumentations
openCV(opencv-python-headless, opencv-python) 등을 이미 설치했다면, 위의 코드 대신 아래 코드를 사용하는 것이 좋다.
1
pip install -U albumentations --no-binary qudida,albumentations
단순한 이미지 변환에 대해서는 documentation을 찾아보면 다 나오고, 가우시안블러, rotation, distortion 등등 다양하게 제공하고 있다. 따라서 여기서는 object detection, semgentation에 대해서만 다룰 것이다.
augmentation for object detection
https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/
albumentations는 pascal_voc, coco, yolo format과 albumentation이라는 파이썬 패키지를 지원한다.

pascal_voc의 경우 [min_x, min_y, max_x, max_y] 의 bbox를 가지고 있고, coco format의 경우 [min_x, y_min, width, height]의 bbox label을 가지고 있다. albumentations는 normalized[min_x, min_y, max_x, max_y] 의 형태이고, yolo는 normalized[center_x, center_y, width, height]를 가지고 있다.
KITTI dataset format을 coco, yolo, pascal voc format으로 변환해보자.
- KITTI Dataset Format
| Values | Name | Description |
|---|---|---|
| 1 | type | Describes the type of object: ‘Car’, ‘Van’, ‘Truck’, ‘Pedestrian’, ‘Person_sitting’, ‘Cyclist’, ‘Tram’, ‘Misc’ or ‘DontCare’ |
| 1 | truncated | Float from 0 (non-truncated) to 1 (truncated), where truncated refers to the object leaving image boundaries |
| 1 | occluded | Integer (0,1,2,3) indicating occlusion state: 0 = fully visible, 1 = partly occluded, 2 = largely occluded, 3 = unknown |
| 1 | alpha | Observation angle of object, ranging [-pi..pi] |
| 4 | bbox | 2D bounding box of object in the image (0-based index): contains left, top, right, bottom pixel coordinates |
| 3 | dimensions | 3D object dimensions: height, width, length (in meters) |
| 3 | location | 3D object location x,y,z in camera coordinates (in meters) |
| 1 | rotation_y | Rotation ry around Y-axis in camera coordinates [-pi..pi] |
| 1 | score | Only for results: Float, indicating confidence in detection, needed for p/r curves, higher is better. |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
import random, sys
import cv2
import numpy as np
from matplotlib import pyplot as plt
import albumentations as A
import albumentations.augmentations.bbox_utils as bbox_utils
BOX_COLOR = (255, 0, 0) # Red
TEXT_COLOR = (255, 255, 255) # White
def my_transform(format : str):
transform = A.Compose([
A.RandomCrop(width=image_width * 3 // 5, height=image_height * 3 // 5),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
A.CLAHE(), # Contrast Limited Adaptive Histogram Equalization,
# clip_limit : upper threshold for contrast, tile_grid_size : size of grid for histogram equalization
A.RandomRotate90(),
A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.50, rotate_limit=45, p=.75),
A.Blur(blur_limit=3),
A.HueSaturationValue(), # randomly change hue, saturation
A.GaussNoise(p=0.5),
], bbox_params=A.BboxParams(format=format, label_fields=['category_ids'])) # label_fields : class numbers e.g. 0,1,2,3,...,8
# class_labels : class name list = category_id_to_name
return transform
def visualize_bbox(img, bbox, class_name, color=BOX_COLOR, thickness=2,
coco : bool = False, yolo : bool = False, pascal : bool = False):
"""Visualizes a single bounding box on the image"""
if coco:
x_min, y_min, w, h = bbox
x_min, x_max, y_min, y_max = int(x_min), int(x_min + w), int(y_min), int(y_min + h)
elif yolo:
cx, cy, w, h = bbox
print("img shape",img.shape, "\nbbox shape", bbox)
cx, w = cx * np.shape(img)[1], w * np.shape(img)[1] # unpack normalize
cy, h = cy * np.shape(img)[0], h * np.shape(img)[0]
x_min, y_min, x_max, y_max = int(cx - w/2), int(cy - h/2), int(cx + w/2), int(cy + h/2)
elif pascal:
x_min, y_min, x_max, y_max = list(map(int,bbox))
print(x_min, y_min, x_max, y_max)
cv2.rectangle(img, (x_min, y_min), (x_max, y_max), color=color, thickness=thickness)
((text_width, text_height), _) = cv2.getTextSize(class_name, cv2.FONT_HERSHEY_SIMPLEX, 0.35, 1)
cv2.rectangle(img, (x_min, y_min - int(1.3 * text_height)), (x_min + text_width, y_min), BOX_COLOR, -1)
cv2.putText(
img,
text=class_name,
org=(x_min, y_min - int(0.3 * text_height)),
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.35,
color=TEXT_COLOR,
lineType=cv2.LINE_AA,
)
return img
def visualize(image, bboxes, category_ids, category_id_to_name):
img = image.copy()
for bbox, category_id in zip(bboxes, category_ids):
class_name = category_id_to_name[category_id]
img = visualize_bbox(img, bbox, class_name, yolo=True)
plt.figure(figsize=(12, 12))
plt.axis('off')
plt.imshow(img)
plt.show()
image = cv2.imread("./od/image.png")
# cv2.imshow("TEST", image)
# cv2.waitKey(0)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
CLASS_TABLE = {
"Car": 0,
"Van": 1,
"Truck": 2,
"Pedestrian": 3,
"Person_sitting": 4,
"Cyclist": 5,
"Tram": 6,
"Misc": 7,
"DontCare": 8
}
image_size = np.shape(image)
image_height = image_size[0]
image_width = image_size[1]
category_id_to_name = dict()
for key, value in CLASS_TABLE.items():
category_id_to_name[value] = key
# TODO YOLO Parse
bboxes = list()
category_ids = list()
with open("od/label.txt", "r", encoding="UTF-8") as od_label:
lines = od_label.readlines()
""" COCO Dataset Format
[x_min y_min width height]
"""
for line in lines:
line = line.split(' ')
class_id = CLASS_TABLE[line[0]]
left = float(line[4])
top = float(line[5])
right = float(line[6])
bottom = float(line[7])
left, top, right, bottom = bbox_utils.normalize_bbox((left, top, right, bottom), image_height, image_width)
width = right - left
height = bottom - top
bboxes.append((left+1e-5, top, width, height))
category_ids.append(class_id)
transform = my_transform(format="yolo")
transformed = transform(image=image, bboxes=bboxes, category_ids=category_ids)
transformed_image = transformed['image']
transformed_bboxes = transformed['bboxes']
visualize(transformed_image, transformed_bboxes, category_ids, category_id_to_name)
albumentations에는 yolo, coco, pascal format을 지원하므로 이에 대해 my_transform에서의 format과 visualize에서의 visualize_bbox의 인자로 어떤 format을 사용할지만 지정해주면 변환이 가능하다. 그러나 yolo의 경우 transform을 할 때 normalize된 bbox를 가져야 하기 때문에 변형시켜줘야 한다. normalize를 해주고, yolo의 경우 (0, 1] 의 범위를 가져야 한다. 따라서 0.0에서 작은 값인 1e-5를 더해준다.
augmentation for segmentation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
import cv2
import numpy as np
from matplotlib import pyplot as plt
import albumentations as A
def visualize(image, mask, original_image=None, original_mask=None):
fontsize = 18
if original_image is None and original_mask is None:
f, ax = plt.subplots(2, 1, figsize=(8, 8))
ax[0].imshow(image)
ax[1].imshow(mask)
else:
f, ax = plt.subplots(2, 2, figsize=(8, 8))
ax[0, 0].imshow(original_image)
ax[0, 0].set_title('Original image', fontsize=fontsize)
ax[1, 0].imshow(original_mask)
ax[1, 0].set_title('Original mask', fontsize=fontsize)
ax[0, 1].imshow(image)
ax[0, 1].set_title('Transformed image', fontsize=fontsize)
ax[1, 1].imshow(mask)
ax[1, 1].set_title('Transformed mask', fontsize=fontsize)
plt.show()
# Read image, mask
def read_image(path):
image = cv2.imread(path, cv2.IMREAD_ANYCOLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image
image = read_image("seg/image.png")
mask = read_image("seg/mask.png")
original_height, original_width = image.shape[:2]
# Augmentation
aug = A.Compose([
A.OneOf([ # choose only one randomly
A.RandomSizedCrop(min_max_height=(50, 101), height=original_height, width=original_width, p=0.5),
A.PadIfNeeded(min_height=original_height, min_width=original_width, p=0.5)
], p=1),
A.VerticalFlip(p=0.5),
A.RandomRotate90(p=0.5),
A.OneOf([
A.ElasticTransform(alpha=120, sigma=120 * 0.05, alpha_affine=120 * 0.03, p=0.5),
A.GridDistortion(p=0.5),
A.OpticalDistortion(distort_limit=2, shift_limit=0.5, p=1)
], p=0.8),
A.CLAHE(p=0.8),
A.RandomBrightnessContrast(p=0.8),
A.RandomGamma(p=0.8)])
augmented = aug(image=image, mask=mask)
image_heavy = augmented['image']
mask_heavy = augmented['mask']
visualize(image_heavy, mask_heavy, original_image=image, original_mask=mask)
oneof 는 저 리스트 중 랜덤으로 1개만을 사용하겠다는 의미이다.
