
7강 리뷰
1) Facier Optimization : 많이 사용되는 강력한 손실함수 최적화 알고리즘
- SGD, Momentum, Nesterov, RMSProp, Adam
2) Regularization : 네트워크의 Train/Test error 간의 격차를 줄이기 위해 사용 (과적합시 이 값을 조정함 - 손실함수에 Regulaization term을 더해 함수를 일반화시킨다)
- dropout
3) Transfer Learning : 미리 학습된 모델을 불러와 데이터만 사용하여 학습시키는 방법
- CPU vs GPU
딥러닝을 진행할 때는 GPU를 사용하는 것이 좋다. GPU 종류 중에서는 NVIDIA 와 AMD가 있는데, AMD의 경우 딥러닝을 수행할 때 문제가 더 많이 발생할 수 있다.
NVIDIA는 딥러닝에 적합한 하드웨어를 만들기 위해 공을 들였기 때문에, 딥러닝에서는 NVIDIA가 독점적으로 많이 사용된다.
CPU는 기본적으로 GPU보다 core의 수가 적다. GPU의 경우 고성능 상업 GPU는 수천개의 코어를 가지고 있다. 코어 수를 가지고 직접적으로 비교하지는 않지만, 코어가 많다는 것은 어떤 일을 수행할 때 병렬로 수행하기 더 적합하다.
또한, CPU는 대부분의 메모리를 RAM에서 끌어다 쓴다. 반면 GPU는 칩 안에 RAM이 내장되어 있다.
따라서 GPU는 딥러닝 연산에 적합하다.
GPU에서 실행되는 코드를 직접 작성할 수 있으나 상당히 어렵고 복잡하다. CUDA, OpenCL, Udacity 등이 있긴 하나 그 대신 편리한 라이브러리를 사용하여 구현하고, GPU를 통해 계산만 실행하면 된다.
Deep Learning Frameworks
딥러닝 프레임워크에는 Pytorch, TensorFlow, Caffe2, MXNet 등이 있지만, 가장 유명한 것은 tensorflow와 pytorch이다.
프레임워크를 사용하는 이유는
- computational graphs를 직접 만들지 않아도 된다.
- forward pass만 잘 구현해놓으면 backpropagation은 알아서 구성된다.
- GPU를 효율적으로 사용할 수 있다.
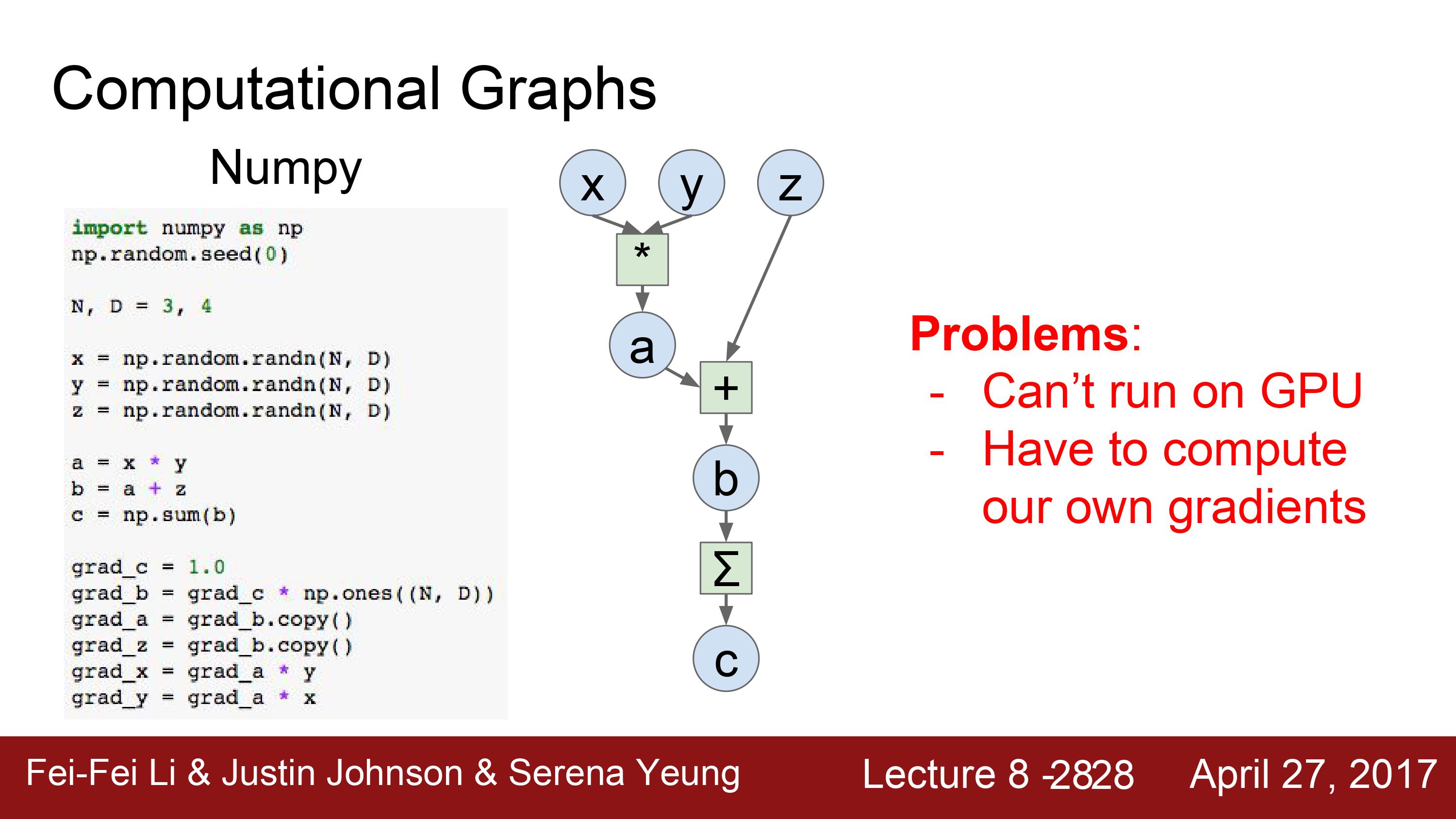
여기 입력 x,y,z에 대한 computational graphs가 있다. 이를 numpy로 작성하면 위와 같은 코드가 될 것이다.
그래프를 numpy로 작성한다면 backward도 직접 작성해야 한다. 이는 매우 까다로운 일이 될 것이다. 또, numpy는 GPU에서 동작하지 않는다.
- Tensorflow
이를 tensorflow로 구현해보자.

tensorflow 코드를 보면 numpy와 유사하다. 하지만 tensorflow에는 gradient를 계산해주는 코드가 존재한다.
1
grad_x, grad_y, grad_z = tf.gradients(c, [x,y,z])
또, tensorflow의 장점은 명령어 한 줄이면 CPU/GPU 전환이 가능하다는 것이다.
1
2
with tf.device('/cpu:0'):
=> with tf.device('/gpu:0'):
CPU:0을 GPU:0으로 바꿔주기만 하면 된다.
- Pytorch
pytorch로 구현해보자.

비슷한 코드로 구성되어 있다.
pytorch 또한 1줄이면 gradient를 계산할 수 있다.
1
c.backward()
GPU를 사용하기 위해서 .cuda()를 붙인다.
각 프레임워크를 좀 더 깊게 살펴보자.
Tensorflow
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
'''
tensorflow neural net
'''
import numpy as np
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior() # placeholder 을 위해 사용
#### computational graphs 구성
N,D,H= 64,1000,100 # number of node, input_size, hidden_size
''' 그래프의 입력 노드 생성, 그래프 밖에서 데이터를 넣어줄 수 있도록 해줌 => session 시에 직접 값을 지정
그래프만 구성하고 실제적인 메모리할당은 일어나지 않는다. '''
x = tf.placeholder(tf.float32,shape=(N,D)) # 입력데이터
y = tf.placeholder(tf.float32,shape=(N,D)) # 입력데이터
w1 = tf.placeholder(tf.float32,shape=(D,H)) # 가중치
w2 = tf.placeholder(tf.float32,shape=(H,D)) # 가중치
''' x와 w1 행렬곱 연산 후 maximum을 통한 ReLU 구현 '''
h = tf.maximum(tf.matmul(x,w1),0) # x와 w1의 행렬곱 연산 -> max(,0)을 이용해 ReLU 함수 구현
y_pred = tf.matmul(h,w2) # h와 w2의 행렬곱 연산 -> 최종 출력값 y_pred 계산
''' L2 Euclidean '''
diff = y_pred-y # 예측값과 실제 정답과의 차
loss = tf.reduce_mean(tf.reduce_sum(diff**2,axis=1)) # 예측값과 실제 정답값 y 사이의 유클리디안 거리를 계산
''' gradient 함수를 통해 loss와, w1, w2의 gradient 계산. backprop 직접 구현할 필요가 없다. '''
grad_w1,grad_w2 = tf.gradients(loss,[w1,w2])
''' ㅡㅡㅡㅡㅡㅡㅡㅡ 그래프 구성 => 아직까지 실제 계산이 이루어지지는 않았다. ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ'''
#### Tensorflow session : 데이터 입력, 실제 그래프를 실행 및 계산
with tf.device('/gpu:0'):
with tf.Session() as sess:
''' 그래프에 들어갈 value 입력. tensorflow는 numpy를 지원한다. '''
values={x:np.random.randn(N,D),
w1: np.random.randn(D,H),
w2:np.random.randn(H,D),
y:np.random.randn(N,D)}
learning_rate = 1e-5
''' 실제 그래프 실행하는 부분, 출력 값은 numpy array '''
for iteration in range(50): # 50번 반복하여 네트워크를 학습한다.
out=sess.run([loss,grad_w1,grad_w2],feed_dict=values) # 첫번째 인자를 통해 그래프의 출력으로 어떤 부분을 원하는지 볼 수 있다. => loss, grad_w1, grad_w2
# feed_dict를 통해 실제 값을 전달
loss_val, grad_w1_val,grad_w2_val = out # output에는 loss와 gradient가 numpy array형태로 반환되어 있기에 각각에 반환한다.
values[w1] -= learning_rate * grad_w1_val # 가중치 업데이트를 위해 gradient를 계산해서 수동으로 gradient diescent하고 있다.
values[w2] -= learning_rate * grad_w2_val # 이 경우 forward pass에서 그래프가 실행될 때마다 가중치를 넣어줘야 한다.
두 개의 fc layer + ReLU 네트워크가 있다. 그리고 손실함수로는 L2 Euclidean을 사용했다.
위의 코드는 크게 2 stage로 나눌 수 있다. 1) computational graph 정의 2) 그래프 실행
위의 코드는 GPU/CPU간의 데이터 교환은 엄청 느리고 비용도 크다.
따라서 아래와 같이 코드를 수정하여 해결한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
import numpy as np
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
N,D,H= 64,1000,100
#### 그래프 구성
x=tf.placeholder(tf.float32,shape=(N,D))
y=tf.placeholder(tf.float32,shape=(N,D))
''' variables로 변경, 변수가 그래프 내부에 있도록 해주는 함수. => session 전에 값을 지정
tf.random_normal로 초기화 설정 '''
w1=tf.Variable(tf.random_normal((D,H)))
w2=tf.Variable(tf.random_normal((H,D)))
h=tf.maximum(tf.matmul(x,w1),0)
y_pred=tf.matmul(h,w2)
diff=y_pred-y
loss = tf.losses.mean_squared_error(y_pred, y) # L2 loss를 직접 구현하지 않고 함수를 불러와 계산
# 이전에는 loss를 계산하는 연산을 직접 만들었다.
# loss=tf.reduce_mean(tf.reduce_sum(diff**2,axis=1))
''' loss 계산, gradient 계산. backprop 직접구현 X '''
grad_w1,grad_w2=tf.gradients(loss,[w1,w2])
''' assign 함수를 통해 그래프 내에서 업뎃이 일어날 수 있도록 해줌 '''
learning_rate=1e-5
# tensorflow는 output에 필요한 연산만 수행한다. 그래서 w1와 w2를 업뎃하라고 명시적으로 넣어주어야 한다.
# new_w1, new_w2를 직접적으로 session 안으로 추가해줄 수 있으나,
# 사이즈가 큰 tensor의 경우 tensorflow가 직접 출력을 하는 것은 cpu/gpu간 데이터 전송이 필요하므로 좋지 않다.
# 따라서 dummy node인 updates 변수를 만들어 그래프에 추가
# update는 어떤 값이 아니라, 특수한 데이터 타입으로 assign operation(작업)을 수행하기 위한 함수 '''
new_w1=w1.assign(w1-learning_rate* grad_w1)
new_w2=w2.assign(w2-learning_rate* grad_w2)
updates=tf.group(new_w1,new_w2)
#### Tensorflow session
with tf.device('/gpu:0'):
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 그래프 내부의 변수들을 초기화, 즉 ,w1,w2를 초기화
values={x:np.random.randn(N,D), # 데이터와 레이블만 넣어줌, 가중치는 그래프 내부에 항상 상주
y:np.random.randn(N,D),} # x,y도 가중치처럼 그래프에 넣어줘도 되지만, x,y가 mini-batch인 경우가 대부분이다.
# 그렇다는 것은 매번 데이터가 바뀌므로 매번 데이터를 넣어줘야 한다.
for i in range(50):
loss_val, _ = sess.run([loss,updates],feed_dict=values) # 그래프를 실행시키면 loss와 dummy node 계산
# _ 는 원래 변수로 사용하던 값을 무시한다는 말이다.
# updates 값은 받지 않고, loss 값만 출력
placeholder을 써서 굳이 매번 가중치를 넣어줄 필요가 없다. 그 대신 variables를 선언해준다. variable은 computational graph안에 서식하는 변수이다.
하지만 이 경우 그래프안에 살기 때문에, 우리가 tensorflow에게 어떻게 초기화시킬 것인지를 알려줘야 한다. 그래프 밖에 있다면 그래프에 넣어주기 전에 numpy를 통해 초기화(tf.random)시킬 수 있지만, 그래프 안에 있다면 초기화시킬 권한은 tensorflow에게 있다.
이전 예제에서는 gradient를 계산하고 그래프 외부(session)에서 numpy로 가중치를 업데이트했다. 계산된 가중치를 다음 스텝에 다시 넣어주었다.
그러나 그래프 안에서 하려면 그 연산 자체가 그래프에 포함되어야 한다. 이를 위해 assign함수를 이용하여 변수가 그래프 내에서 업데이트 되도록 한다.
updates는 tensorflow의 트릭중 하나다. 그래프를 구성하는 동안에는 복잡한 객체를 반환하지만, session.run을 동작시키면 none을 반환(_)하게 된다.
하지만, 사실 위의 방법은 좋은 방법은 아니다. 대신에 optimizer을 사용할 수 있다. assigns줄부터 updates줄까지를 아래와 같이 바꾸기만 하면 된다.
1
2
3
4
5
optimizer = tf.train.GradientDescentOptimizer(learning_rate) # 이 외에도 Adam, RMSprop 등 optimization 알고리즘 사용 가능
# 그래프에 w1,w2의 gradient를 계산하는 노드도 알아서 추가하고,
# w1,w2의 update opertation도 알아서 추가한다.
# assign을 위한 grouping opertation도 추가된다.
updates = optimizer.minimize(loss) # loss는 최소값을 찾아야 하므로 minimize
입력과 가중치를 정의하고 행렬 곱연산으로 묶는 일이 번거롭기에 tf.layers로 간편하게 변경시킬 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
N,D,H= 64,1000,100
''' 그래프의 입력노드 생성 '''
x=tf.placeholder(tf.float32,shape=(N,D))
y=tf.placeholder(tf.float32,shape=(N,D))
''' Xavier initializer로 초기화 '''
init=tf.contrib.layers.xavier_initializer() # 초기화 방법 선언, 기존에는 tf.randomnormal로 일일이 초기화시켰다.
''' w1, b2를 변수로 만들어주고 초기화 '''
h=tf.layers.dense(inputs=x,units=H,activation=tf.nn.relu,kernel_initializer=init) # w1과 w2를 variables로 만들어주고, 그래프 내부에 적절한 shape으로 만들어준다.
# activation을 통해 layer에 relu를 추가해준다.
y_pred=tf.layers.dense(inputs=h,units=D,kernel_initializer=init) # 이전 h를 받아서 똑같이 수행한다.
loss=tf.losses.mean_squared_error(y_pred,y)
# optimizer을 이용해서 gradient를 계산하고 가중치를 업뎃할 수 있다
optimizer=tf.train.GradientDescentOptimizer(1e-5)
updates=optimizer.minimize(loss)
## Tensorflow session
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
values={x:np.random.randn(N,D),
y:np.random.randn(N,D)}
for t in range(50):
loss_val=sess.run([loss,updates],feed_dict=values)
위는 tf.contrib.layer과 tf.layer을 사용한 편리한 방법이다. 하지만 더 다양하고 향상된(high level) 라이브러리가 있다.
그리고, 위의 코드들은 computational graph를 다루고 있다. 이는 low level이지만, 우리가 앞으로 다루어야 할 것들은 Neural Network인데, 이는 high level이다.
그래서 tensorflow와 keras를 활용한 Network를 만들어보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.optimizers import SGD
N, D, H = 64, 1000, 100
model = Sequential() # 모델을 구성하기 위한 큰 틀과 같은 것
model.add(Dense(input_dim=D, output_dim= H)) # 한 층 추가
model.add(Activation('relu')) # 활성함수 추가
model.add(Dense(input_dim=H, output_dim= D)) # 한 층 추가
optimizer = SGD(lr = 1e0) # optimizer 선언
model.compile(loss = 'mean_squared_error', optimizer = optimizer) # loss와 optimizer를 사용하여 그래프 생성
x = np.random.randn(N, D) # 데이터 입력
y = np.random.randn(N, D) # 데이터 입력
history = model.fit(x, y, nb_epoch = 50, batch_size = N, verbose = 0) # model 50번 실행
tensorflow 기반 high level wrapper(함수? 라이브러리?)
- Keras https://keras.io/
- TFLearn http://tflearn.org/
- TensorLayer http://tensorlayer.readthedocs.io/en/latest/
- tf.layers https://www.tensorflow.org/api_docs/python/tf/layers
- TF-Slim https://github.com/tensorflow/models/tree/master/inception/inception/slim
- tf.contrib.learn https://www.tensorflow.org/get_started/tflearn
- Pretty Tensor https://github.com/google/prettytensor
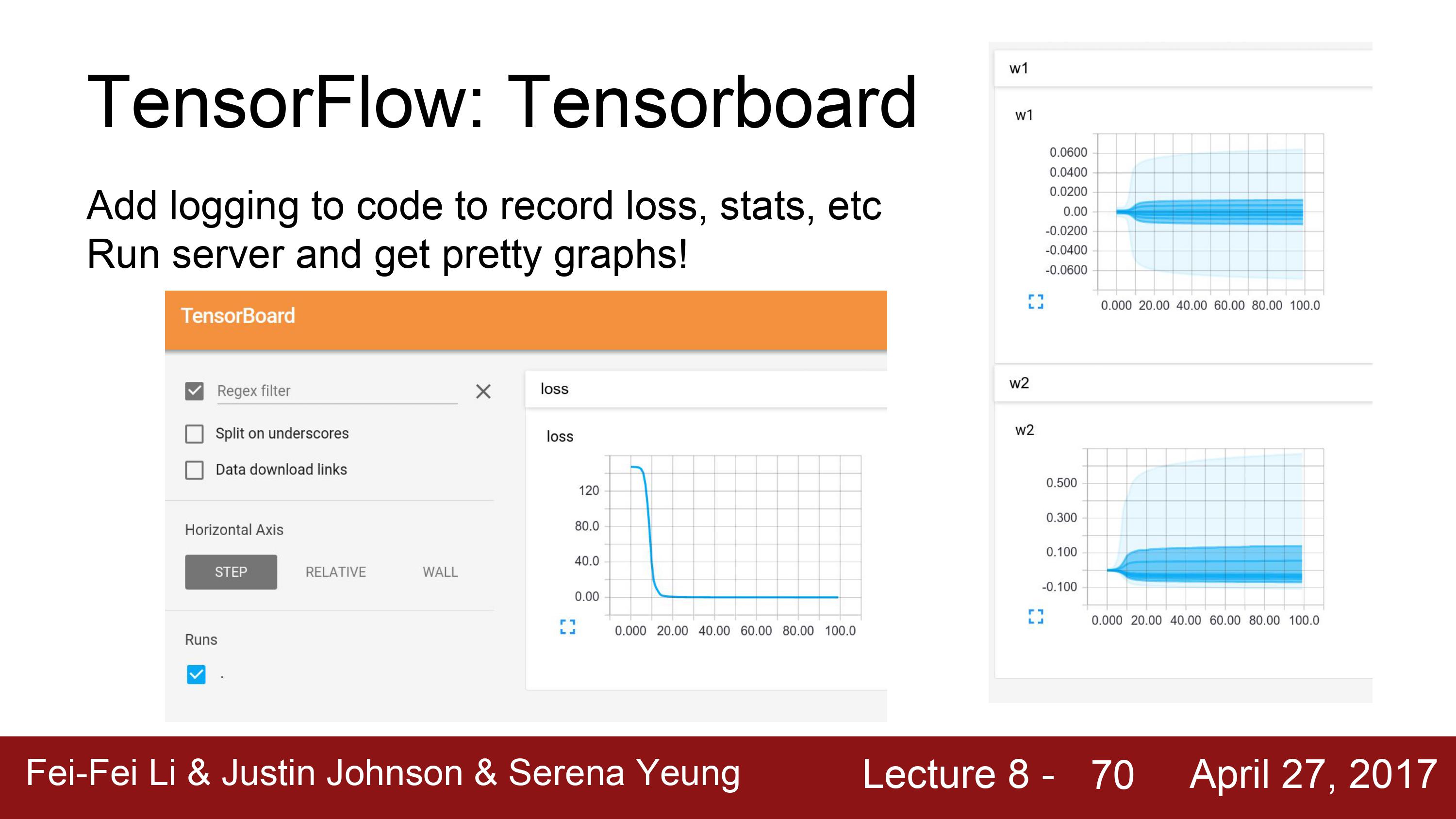
tensorboard를 통해, tensorflow를 사용할 때 training 하는 동안 loss와 같은 통계값들을 시각화할 수 있다.
Pytorch
pytorch에는 3가지 중요한 요소들이 있다
- tensor: imperative(명령형) array, gpu에서 사용가능, tensorflow의 numpy array와 같은 역할
명령형 언어 vs 선언형 언어의 차이 설명 참고 : https://blog.naver.com/66dlwjddbs66/221826016905
- variable: 그래프의 노드, 그래프를 구성하고 gradient를 계산할 수 있음, tensorflow의 variable,placeholder과 같은 역할
- module: Neural Network를 구성, tf.layer과 같은 역할
아래는 pytorch tensor로 구성한 2-layer Network이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import torch
dtype=torch.cuda.FloatTensor # gpu에서 돌아가도록 데이터 타입을 변경
# gpu사용을 위해 FloatTensor 대신 cuda.FloatTensor로 변경
N,D_in,H,D_out=64,1000,100,10
''' random data 선언 '''
x=torch.randn(N,D_in).type(dtype)
y=torch.randn(N,D_out).type(dtype)
w1=torch.randn(D_in,H).type(dtype)
w2=torch.randn(H,D_out).type(dtype)
learning_rate=1e-6
for i in range(500):
''' forward pass '''
h = x.mm(w1) # mm : 행렬 곱 연산 함수 -> x와 w1을 행렬 곱 연산하여 h에 저장
h_relu = h.clamp(min=0) # clamp : min/max 를 통해 값을 바꾸는 함수, min = 0 이라면 0보다 작은 값들은 0으로 치환 -> relu 형태로 만듦
y_pred = h_relu.mm(w2) # h와 w2를 연산하여 pred로 출력
loss=(y_pred-y).pow(2).sum() # loss 계산, pow는 제곱 함수 -> L2 euclidean distance
''' backward pass
backward 직접 구현 - > gradient 계산 '''
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t()) # 행렬 곱 연산
grad_h[h>0] = 0 # relu
grad_w1 = x.t().mm(grad_h)
''' 가중치 업데이트 '''
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
따로 그래프를 구성하는 코드가 없다.
아래는 variable을 사용하여 구현한 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import torch
from torch.autograd import Variable
N,D_in,H,D_out=64,1000,100,10 # number of node, input_size, hidden_size, output_size
''' variable은 computational graph를 만들고 이를 통해 gradient를 자동 계산하는 목적으로 사용
x는 variable, x.data는 tensor, x.grad는 variable, x.grad.data도 tensor
x.grad.data는 gradient 정보를 담고 있다. '''
x = Variable(torch.randn(N,D_in),requires_grad=False) # 이 값의 gradient를 계산할 것인지 지정할 수 있다.
y = Variable(torch.randn(N,D_out),requires_grad=False) # 앞서 복잡한 gradient 계산 과정을 압축시킬 수 있음
w1 = Variable(torch.randn(D_in,H),requires_grad=True) # 가중치에 대한 gradient만 계산
w2 = Variable(torch.randn(H,D_out),requires_grad=True)
learning_rate=1e-6
for t in range(500):
''' forward pass '''
y_pred=x.mm(w1).clamp(min=0).mm(w2) # 출력값 계산 후 relu 연산
loss=(y_pred-y).pow(2).sum() # loss 계산
''' backward pass '''
if w1.grad: w1.grad.data.zero_() # w1.grad 초기화
if w2.grad: w2.grad.data.zero_() # w2.grad 초기화
loss.backward() # gradient가 알아서 반환되어 backward 진행
''' w.grad.data를 이용해 가중치 업데이트 '''
w1.data-=learning_rate* w1.grad.data
w2.data-=learning_rate* w2.grad.data
- Tensorflow vs Pytorch
먼저 tensorflow의 경우 그래프를 명시적으로 구성한 후 그래프를 돌린다. 즉 session 전에 그래프를 구성하고 session을 통해 계산한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
''' 그래프의 입력노드 생성 '''
x=tf.placeholder(tf.float32,shape=(N,D))
y=tf.placeholder(tf.float32,shape=(N,D))
''' Xavier initializer로 초기화 '''
init=tf.contrib.layers.xavier_initializer()
''' w1, b2를 변수로 만들어주고 초기화 '''
h=tf.layers.dense(inputs=x,units=H,activation=tf.nn.relu,kernel_initializer=init)
y_pred=tf.layers.dense(inputs=h,units=D,kernel_initializer=init)
loss=tf.losses.mean_squared_error(y_pred,y)
반면 pytorch의 경우 forward pass 할 때마다 매번 그래프를 다시 구성한다.
1
2
3
4
for t in range(500):
''' forward pass '''
y_pred=x.mm(w1).clamp(min=0).mm(w2) # 출력값 계산 후 relu 연산
loss=(y_pred-y).pow(2).sum() # loss 계산
추가적으로 autograd를 직접 제작할 수 있다.

하지만, 대부분의 경우 직접 구현하기보다, 원래 있는 모델을 사용하는 것이 좋다.
pytorch에는 nn module이 존재한다. 이는 DNN 구성시 매우 많이 사용된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import torch
from torch.autograd import Variable
N,D_in,H,D_out=64,1000,100,10
learning_rate=1e-4
x=Variable(torch.randn(N,D_in))
y=Variable(torch.randn(N,D_out),requires_grad=False)
model = torch.nn.Sequential( # layer 생성
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H,D_out))
loss_fn=torch.nn.MSELoss(size_average = False) # common loss function, mean squared error loss(평균제곱오차)
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate) # optimizer를 위해 Adam 알고리즘 선언
for t in range(500):
''' forward pass, prediction, loss 계산 '''
y_pred=model(x) # model에 x 넣고 prediction
loss=loss_fn(y_pred,y) # prediction과 실제값 y를 통해 loss 계산
''' backward pass, gradient 계산 '''
optimizer.zero_grad() # grad 초기화
loss.backward() # gradient 자동 계산
optimizer.step() # model parameter 업데이트
''' optimizer.step을 풀어쓰면 아래와 같다.
for param in model.parameters():
param.data-=learning_rate*param.grad.data
'''
자신만의 모델을 구축해보자.
여기 2-layer Network 예제가 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import torch
from torch.autograd import Variable
from torch.utils.data import TensorDataset, DataLoader
''' 단일 모듈(class)로 model 생성
backward는 autograd가 알아서 해줌 '''
class TwoLayerNet(torch.nn.Module):
def __init__(self, D_in, H, D_out): # layer 정의
super(TwoLayerNet, self).__init__() # super : 부모 클래스 함수의 메서드를 실행 가능하게 해줌,
# __init__ : 우리는 객체(인스턴스) 생성시 매번 해주어야 하는 번거로운 작업을 간단하게 만들어줌
self.linear1=torch.nn.Linear(D_in,H) # Linear 구성
self.linear2=torch.nn.Linear(H,D_out) # Linear 구성
def forward(self,x): # forward pass 정의
h_relu=self.linear1(x).clamp(min=0) # 1층 layer 출력을 relu 연산 후 h_relu에 저장
y_pred=self.linear2(h_relu) # 2층 layer 출력을 y_pred 에 저장
return y_pred # y_pred 출력
N,D_in,H,D_out=64,1000,100,10
x=Variable(torch.randn(N,D_in))
y=Variable(torch.randn(N,D_out),requires_grad=False)
''' DataLoader가 minibatching, shuffling, multithreading 관리
minibatch를 가져오는 작업들을 multi-threading을 통해 알아서 관리해준다. '''
ds = TensorDataset(x, y) # 미리 정리된 TensorDateset을 불러옴
loader = DataLoader(ds, batch_size=8) # dataset을 dataloader을 통해 loader함
model = TwoLayerNet(D_in, H, D_out) # 정의했던 Net을 이용해 model을 불러옴
criterion=torch.nn.MSELoss(size_average=False)
optimizer=torch.optim.Adam(model.parameters(),lr=1e-4)
for epoch in range(10):
''' forward pass '''
for x_batch, y_batch in loader:
x_var, y_var=Variable(x),Variable(y) # mini-batch단위로 나뉘어진 loader를 각 epoch마다 x,y에 계속 입력시켜야 한다.
y_pred=model(x_var)
loss=criterion(y_pred,y_var)
''' backward pass '''
optimizer.zero_grad()
loss.backward()
optimizer.step()
pretrained model을 불러와 사용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import torch
import torchvision
from torchsummary import summary
resnet101 = torchvision.models.resnet101(pretrained=True)
''' 불러온 모델 구조 확인 방법 '''
summary(resnet101, (3,224,224),device='cuda')
print(resnet101)
>>>
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 4,096
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 16,384
BatchNorm2d-12 [-1, 256, 56, 56] 512
Conv2d-13 [-1, 256, 56, 56] 16,384
BatchNorm2d-14 [-1, 256, 56, 56] 512
ReLU-15 [-1, 256, 56, 56] 0
Bottleneck-16 [-1, 256, 56, 56] 0
tensorboard와 같이 pytorch에서도 visdom을 통해 loss에 대한 통계같은 값들을 시각화 할 수 있다.

Static(tensorflow) Vs Dynamic(pytorch) graph

먼저 tensorflow는 두 단계로 나눌 수 있다. 그래프를 구성하는 단계, 두번째는 그래프를 반복적으로 실행하는 단계이다.
그래프가 단 하나만 고정적으로 존재하는 형태를 static computational graph라고 한다.
반면 pytorch의 경우 매번 forward pass할 때마다 새로운 그래프를 구성한다.
이를 dynamic computational graph라 한다.
단순한 과정에서는 별 차이 없어보이지만, 차이점은 분명 존재한다.
static graph는 한번 그래프를 구성해놓으면 학습시에 계속 똑같은 그래프를 재사용한다. 그렇다는 것은 그래프를 최적화시킬 수 있다는 것을 의미한다.
일부 연산들을 합치거나 재배열시키는 등으로 가장 효율적으로 연산하도록 최적화시킬 수 있다는 것이다.
처음에는 최적화작업이 오래걸리지만, 최적화한 그래프를 여러번 사용하기 때문에, 손해가 아니다.
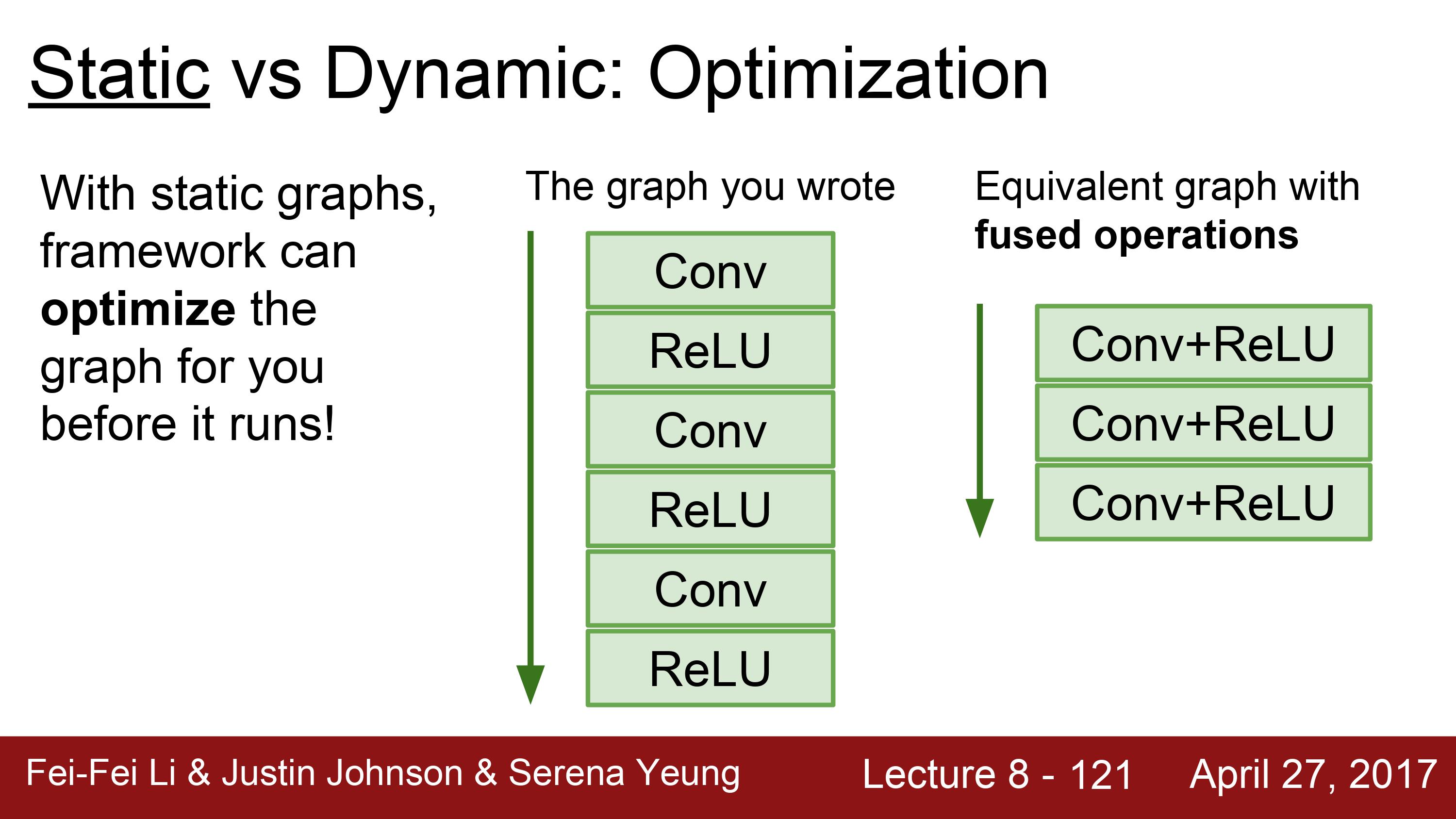
예를 들어, 여기 Conv와 Relu를 합쳐버릴 수 있다.
반면 dynamic graph에서는 그래프를 최적화하기 어렵다.
또 다른 차이점으로는 serialization에 관한 것이다.
static graph를 사용한다고 해보자. 그래프를 한 번 구성해놓으면 메모리 내에 그 네트워크 구조를 가지고 있게 된다. 그렇다는 것은 그래프 자체, 네트워크 구조 자체를 disk에 저장할 수 있다. 이렇게 되면 전체 네트워크 구조를 파일 형태로 저장할 수 있다. 그러면 원본 코드 없이도 그래프를 다시 불러올 수 있다.
python에서 불러올 수 있을 뿐만 아니라 c++에서도 불러 올 수 있다.
반면 dynamic graph의 경우 그래프 구성과 그래프 실행하는 과정이 묶여 있다. 그렇기에 그래프를 다시 불러오기 위해서는 항상 원본 코드가 필요하다.
하지만 dynamic은 대다수의 경우에 코드가 훨씬 깔끔하고 작성하기 더 쉽다.

if문을 만들 때, pytorch는 단순하게 if문을 사용하면 된다.
하지만 tensorflow의 경우 우선 그래프를 만들고 난 후 그래프 내에 조건부 연산을 정의하는 코드가 더 필요하다. 때문에, if문 대신 control flow 자체를 넣어줘야 한다. 그래프가 실행되기 전에 연산을 넣는 것이다.

또한, 반복연산(loops)에서도 차이점이 있다.
우리의 데이터는 다양한 사이즈일 수 있다. 데이터의 길이가 얼마인지 신경쓰지 않고 재귀 연산을 할 수 있다면 좋을 것이다.
pytorch의 경우 기본적인 for문을 사용하면 된다.

그러나 tensorflow에서는 그래프를 앞에서 미리 만들어줘야 하기 때문에, 그래프에 명시적으로 loop를 넣어줘야만 한다.
특정 재귀적인 관계를 정의하기 위해 tf.fold1연산을 사용한다. fold는 dynamic graph처럼 만들어주기 위한 트릭이다.
정리하자면
static graph
- 그래프를 구성해놓으면 재사용이 가능, 즉 그래프를 최적화시킬 수 있다.
ex) conv -> relu -> conv -> relu ==> conv+relu -> conv+relu
- 그래프를 구성 -> 네트워크 구조 자체를 disk에 저장 가능 -> 파일 형태로 네트워크 구조를 저장 가능 -> 원본 코드 없이 그래프 다시 불러오기가 가능
- 조건부 연산(if 문) 그래프를 따로 만들어야 함
dynamic graph
- forward pass할때마다 그래프를 구성 -> 그래프를 최적화하기 어려움
- 모델을 다시 불러오기 위해서는 항상 원본 코드 필요
- 대신 코드가 더 깔끔하고 작성하기 쉬움
그렇다면 어떤 상황에서 dynamic graph를 사용해야 할까?
최근 나온 network인 image captioning이 있다. image captioning은 다양한 길이의 sequences(출력)를 다루기 위해 RNN을 이용한다.
sequence는 입력 데이터에 따라서 다양하게 변할 수 있다. sequence의 크기에 따라 computational graph가 커질 수도, 작아질 수도 있다.
따라서 image captioning은 dynamic graph를 이용할 일반적인 예시 중 하나다.
또는, 자연어 처리 분야에서 문장을 파싱하는 문제에서 트리를 파싱하기 위해 recursive(반복)한 네트워크가 필요할 수 있다.
이런 경우 layer의 sequence 구조를 이용하기 보다 graph나 tree 구조를 이용한다. 즉, 데이터에 따라 다양한 graph나 tree 구조를 가질 수 있다.
이 때, tensorflow로 구성하려면 정말 복잡하고 까다롭다. 따라서 dynamic graph를 사용하는 것이 좋다.
VQS를 다루는 neuro module(신경 모듈)이라는 연구가 있다. 이미지와 질문을 던지면 적절한 답을 해주는 것이다.
질문에 따라 그 질문의 답을 위한 적절한 네트워크를 구성한다. 또, 질문이 물체 2개를 비교하는 것이라면 find, count와 compare을 수행해야 할 것이다.
Caffe
다른 딥러닝 프레임워크랑 다소 다르게 코드를 작성하지 않아도 네트워크를 학습시킬 수 있다.
기존에 빌드된 바이너리를 호출하고 configuration 파일만 조금 수정하면 코드를 작성하지 않아도 데이터를 학습시킬 수 있다.
training 과정
- 데이터를 HDF5 또는 LMDB포맷으로 변환시킨다.
- 코드 작성 대신 prototxt라는 텍스트파일을 만든다.
- 입력은 HDF5파일로 받는 부분도 있고 내적을 하는 부분도 있다. 이런 형식으로 그래프를 구성한다.
- 훈련시킨다.
이런 방식은 네트워크의 규모가 커지면 상당히 보기 안좋다. 152layer 모델을 훈련시키려면 prototxt는 거의 7000줄이 된다.
그래서 prototxt생성 대신 python 스크립트를 작성한다.
caffe는 그래프를 하나하나 전부 다 기술해줘야 한다. 또, optimizer이나 solver을 정의하기 위해 또 다른 prototxt 파일을 작성해야 한다.
caffe에도 pretrained model을 제공한다. alexnet,vgg,googlenet,resnet 등등이 있다.
caffe는 산업이나 생산 개발에 많이 쓰인다.
Caffe2
caffe2는 caffe의 다음 버전이다.
caffe2는 static graph를 사용한다. caffe와 같이 C++로 작성되어 있고, python 인터페이스도 제공한다.
caffe와 차이점은 더이상 prototxt파일을 만들기 위해 python 스크립트를 작성할 필요가 없다는 것이다.
