
- 4강 리뷰
1) backpropagation
2) Calculation of the local gradient in computational graph.
3) Neural Network
- linear layer을 쌓고 그 사이에 비선형 layer를 추가하여 neural network를 만듦
History of Convolutional Neural Network
이제 우리가 배울 것은 Convolutional layer이다. 이 layer은 Spatial Structure를 유지한다.
1957년 최초로 perceptron을 구현했고, 여기서 가중치 w를 업데이트하는 방법이 처음 등장했다.
1960년에 multi-layer perceptron network(MLP Network)를 발명했다.

1986년에 backpropagation이 등장했고, 신경망의 학습이 시작되었다. 2006년에 deep learning의 학습 가능성이 거론되면서 전체 신경망을 backpropagation하거나 fine-tuning하는 식으로 진행되었다.
1
model = models.resnet34(pretrained = True)
하지만 컴퓨터 속도와 용량 등의 환경적 요인에 의해 연구가 진행되기 어려웠다.
그러다 2012년 imageNet 분류를 통해 에러를 극적으로 감소시키는 AlexNet이 처음 등장하면서 CNN이 알려지기 시작했다.

AlexNet에서 처음으로 batch normalization을 사용했고, GPU를 2대 활용하여 대규모의 데이터를 활용하였다.
CNN은 이미지 classification, 이미지 검색, 객체 탐지, segmentation, Lidar와 함께 자율주행, 얼굴 인식, 비디오 분석, 포즈 평가 등 다양하게 활용되고 있다.
CNN
- Fully-Connected Layer
FC layer에서 하는 일은 어떤 벡터를 가지고 연산을 하는 것이다.
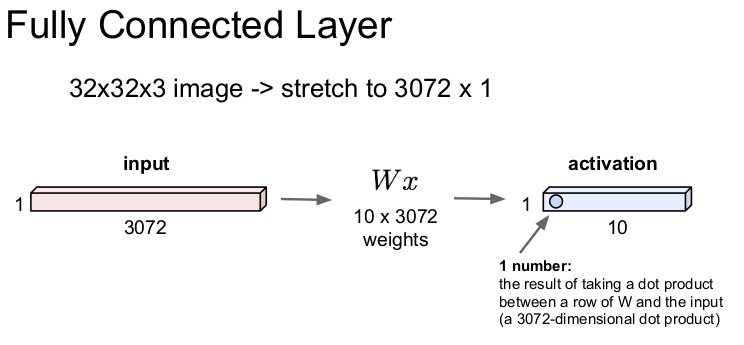
- 우선 32x32x3 image를 input한다.
- 이 이미지를 길게 펴서 3072x1차원의 벡터로 만든다.
- 가중치 w를 곱한다. (W*x) - 이 예시에서는 w는 10x3072 행렬
- activation, 즉 output을 얻는다. - 1x10 크기로 출력 될 것이다. 즉 class가 10개고, 그에 대한 각각의 score가 나올 것이다.
Convolution layer
convolutional layer와 기존의 FC layer의 차이점은 conv layer는 기존의 구조를 그대로 보존시킨다는 것이다.
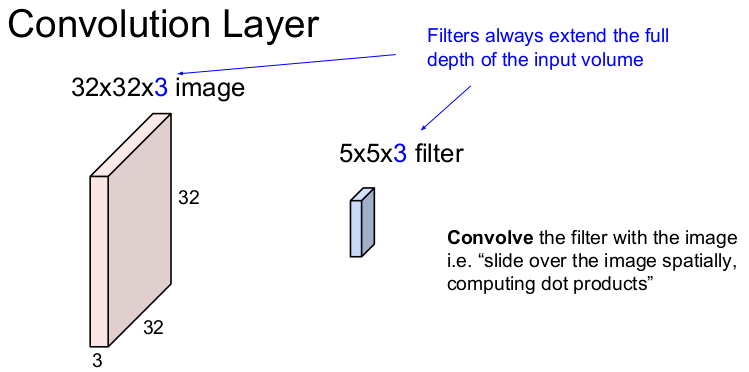
이 작은 5x5x3 filter가 우리가 가진 가중치가 되는 것이다.
filter의 각 w와 공간적 내적을 통해 숫자를 출력한다. 즉, 32x32x3의 입력 이미지에 5x5의 filter를 슬라이딩하면서 값을 추출하는 것이다.
이때, 3이 의미하는 것은 RGB, 3채널을 뜻하고 depth라고 부른다. filter depth은 입력 이미지의 depth과 동일하게 부여해야 한다.
convolution layer에서는 filter의 depth을 제외한 나머지의 크기(ex. 5x5)를 정할 수 있다.
입력 이미지에 filter를 슬라이딩하여 내적을 구하는 것을 convolve한다고 한다.
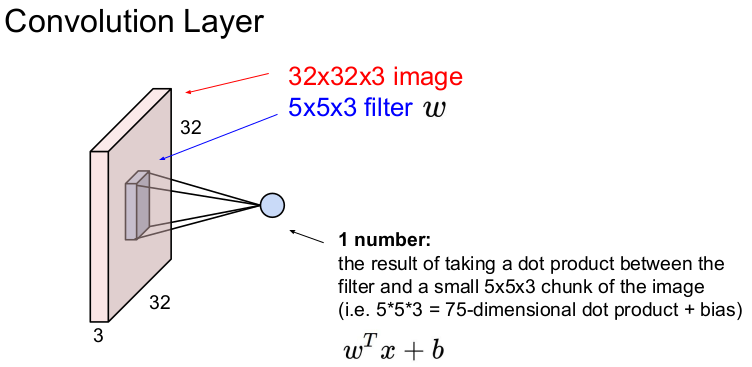
기본적으로 계산은 w^T * x + b (b: bias term) 의 식으로 내적을 계산한다.

image가 5x5, filter이 3x3 일 경우 5x5 중에서 filter의 크기인 3x3크기만큼만 filter과 내적을 통해 1개의 결과값을 출력한다. 이를 이미지 좌측 상단부터 우측 하단까지 모든 픽셀을 슬라이딩하면서 계산을 하게 되는 것이다.
위의 사진을 참고했을 때, 다음 계산은 [(4 1 2),(1 1 0),(2 1 0)] 과 filter의 내적이 된다.
이 1개의 숫자가 나오는 계산식이 w^T * x + b이다.
이 슬라이딩을 통해 얻은 값을 모으면 28x28x1의 이미지가 되는데, 이를 activation map이라 한다.
출력된 activiation map의 크기는 filter의 크기와 숫자 그리고 슬라이딩을 어떻게 하느냐에 따라 달라진다.
보통 convolution layer에서는 여러 개의 필터를 사용한다. 필터마다 다른 특징을 추출할 수 있기 때문이다.
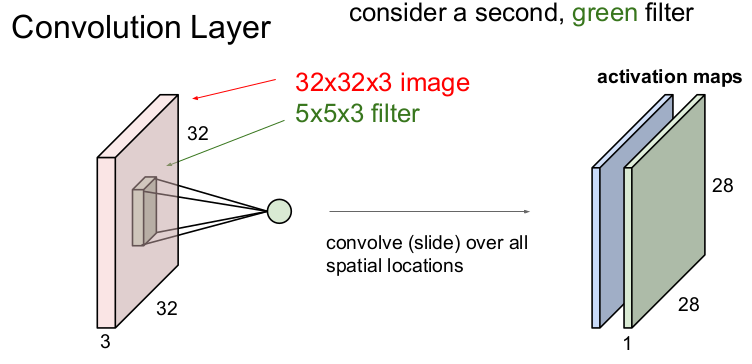
5x5x3의 또 다른 초록색 필터를 가져왔다. 이를 슬라이딩하여 동일하게 28x28x1의 activation map을 얻을 수 있다.
6개의 필터를 사용하게 되면 총 6개의 map을 얻을 수 있다. 이렇게 나온 activation map을 모아 크기 28x28x6 의 map을 만들 수 있다.
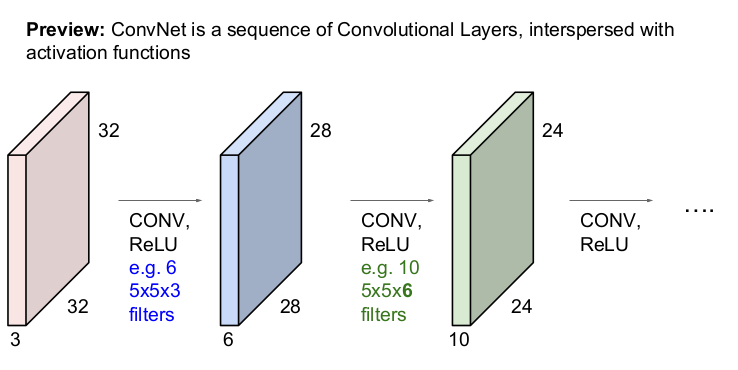
사이 사이에 ReLU와 같은 actiavtion function을 넣어 conv-ReLU가 반복시킬 수 있다. 또한, 중간 중간에 pooling layer도 추가하기도 한다.
위의 그림은 32x32x3의 input image를 6개의 5x5x3 filter 6개를 각각 슬라이딩 하여 28x28x6의 activation map을 얻는다.
이 activation map이 다시 input image가 되어 10개의 5x5x6 filter를 통해 24x24x10의 activation map을 얻는다.
pooling layer
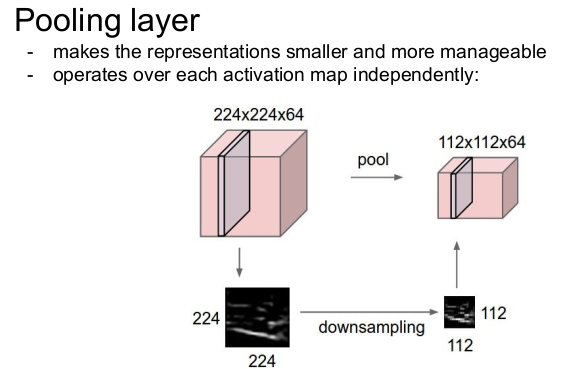
pooling layer는 convolution시 downsampling을 할 때 이미지의 크기를 줄이면 데이터의 손실이 발생할 수 있다. 정보를 최대한 보존하면서 크기를 줄이기 위해 stride 값을 1로 지정하고 pooling을 통해 크기를 줄인다.
또한 pooling을 하면 overfitting을 막을수도 있다. 입력 데이터에 과도하게 맞춰지는 경우를 방지하는 것이다.
즉, 입력 데이터로 학습한 데이터만 정답으로 인식하고, 그 데이터의 회전, 특정 좌표로 이동, 자름 등의 이미지에 대해서는 유연하지 못한 것을 방지한다.
pooling 중에서도 max pooling을 주로 사용하는데, max pooling 이란 pool size내에서 최댓값만 뽑아내는 것을 말한다.

위의 그림은 2x2 max pooling 하는 과정이다. 첫번째 그림의 경우 1 2 0 1 중에서 가장 큰 2를 골라 추출한다.
Pooling은 파라미터의 수를 줄이기 때문에 관리가 쉽고, 이미지의 차원을 공간적으로 줄여준다. 하지만 depth는 줄이지는 못한다.
또한 pooling은 downsampling을 위해 사용하기 떄문에, pooling할 때 비슷한 역할인 padding하지는 않는다.
padding
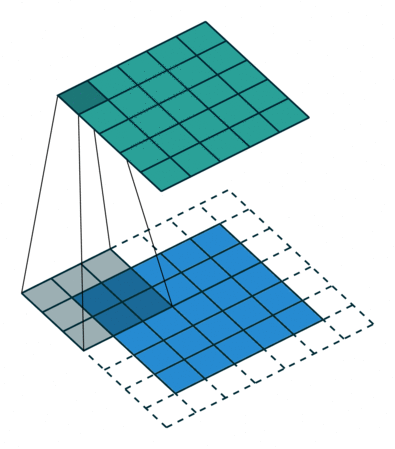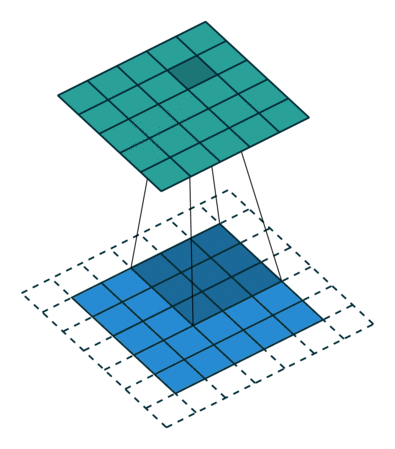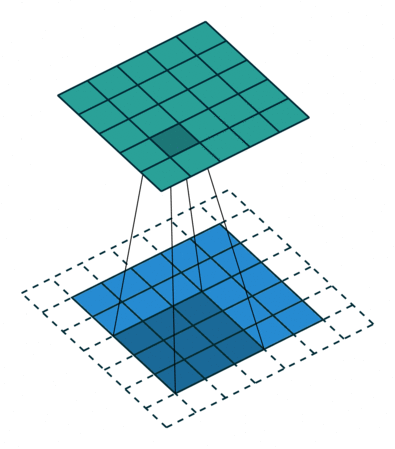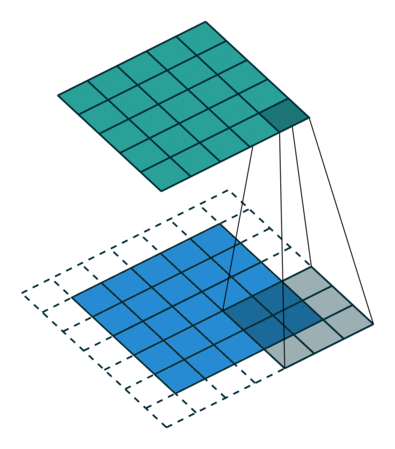
필터를 적용할 때, 모서리에 있는 이미지 데이터의 정보는 중앙에 있는 정보보다 비교적으로 적게 연산되므로 이를 조절해주기 위한 방법이다.
즉, 패딩은 출력 데이터의 공간적 크기를 조절해주기 위해 사용하는 파라미터다. 공간적 크기를 조절하여 모서리에 있는 데이터 정보에 대한 연산 수와 중앙에 있는 데이터 정보에 대한 연산 수를 얼추 맞춰 정보가 누락되지 않도록 한다.
입력 데이터의 크기와 출력 데이터의 크기를 같게 해주는 것을 zero-padding이라 한다.
zero-padding은 입력 이미지 바깥에 0으로 이루어진 pixel을 넣어주는 것이다.

따라서 conv layer에서는 zero padding으로 출력 이미지의 크기와 데이터를 보존하고, 이미지의 크기를 줄이는 것은 pooling에서 진행한다.
stride
입력 데이터와 필터를 연산할 때 기본적으로 1칸씩 움직이면서 연산한다. 이를 stride 값이 1이라 할 수 있다.
즉, stride는 입력 데이터에 필터를 적용할 때 이동할 간격을 조절해주는 파라미터다.
pooling 과 stride는 기능은 비슷하나 stride가 조금 더 좋은 성능을 보이기 떄문에 stride를 더 많이 쓰는 추세다.
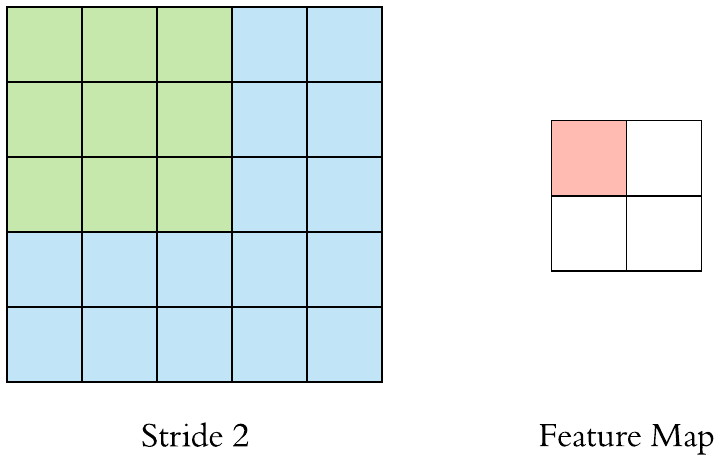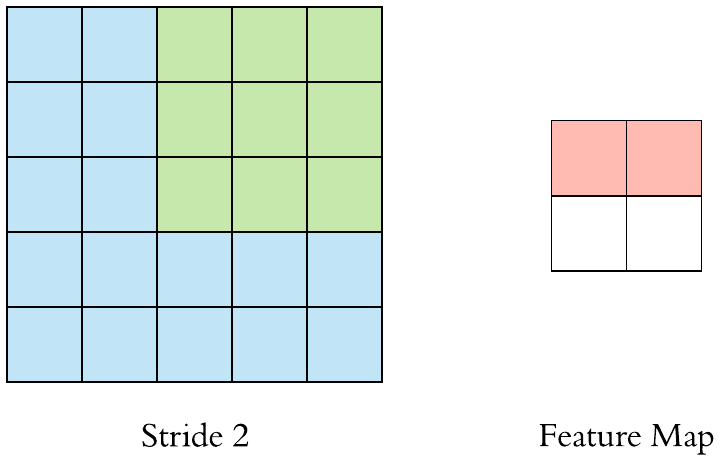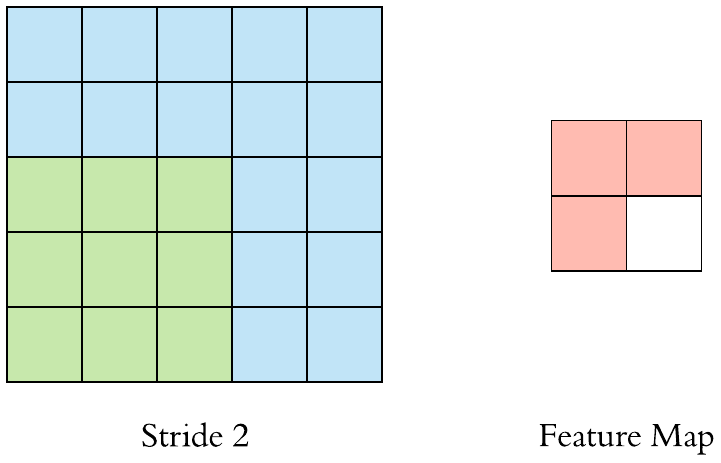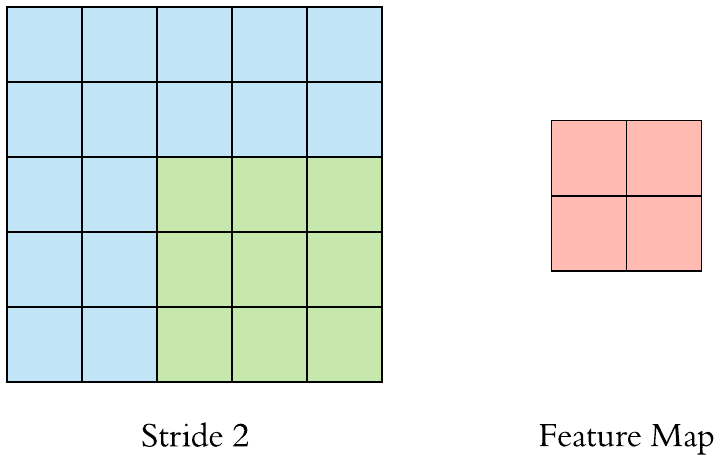
stride = 2 일 때의 pooling을 진행하는 모습이다.
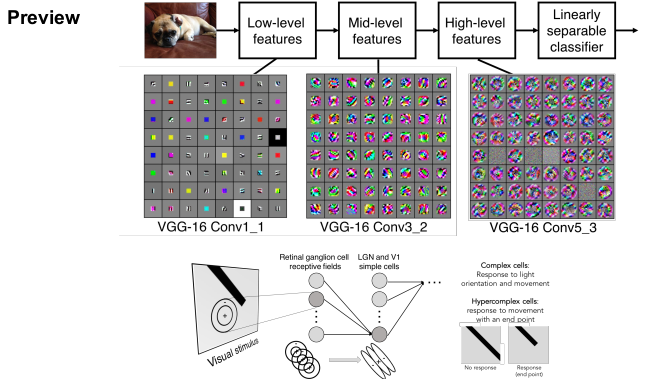
여러 개의 layer을 쌓다보면 각 필터들이 계층적으로 학습한다.
앞쪽 필터 즉, 입력층과 가까울수록 low-level feature을 학습한다. 뒤로 갈수록 점점 복잡해져 객체와 닮은 것들이 출력으로 나오는 것을 볼 수 있다.
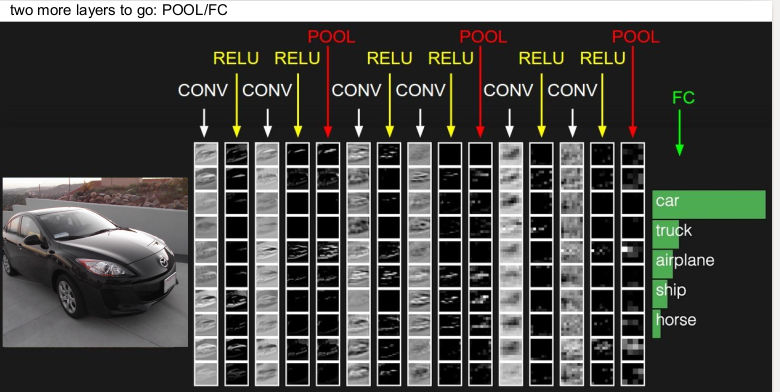
수많은 conv-relu-pooling layer들을 지나 마지막에는 3D conv output을 1차원으로 펴서 FC(fully connected) layer에 집어넣어 최종 스코어를 계산한다.
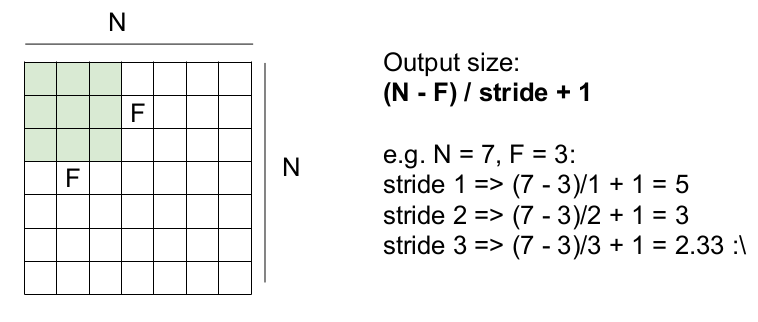
activation map의 차원을 구하는 공식은 다음과 같다.
1
2
3
4
NxNx3 input image, fxfx3 filter 일 경우 activation map 의 크기는 :
[(N - f + 1)/stride size] x [(N - f + 1)/stride size]x number of filter
ex) N=6 , f=2, 5개 filter, stride=2 => 3x3x5 의 activation map
예를 들어 32x32x3 의 입력 이미지를 10개의 5x5 filter를 stride=1, padding=2 로 convolution 한다면
output size는 32x32x10이다.
padding=2 이므로 양쪽에 2씩 더한 후 [{(32 + 2*2)-5}/1] + 1 = 이므로 32가 된다.
이 때 파라미터의 개수는
5 * 5 * 3 + 1(bias) = 76개의 파라미터를 가지고, 필터의 개수 10을 곱하면 760개의 파라미터가 존재한다.
보통 filter의 갯수는 2의 제곱수로 설정하고, stride는 1 or 2로 설정한다. 필터는 3x3 또는 5x5를 많이 사용한다.
1x1 convolution layer
이미지의 depth 크기를 줄이는 방법으로 1x1 convolution layer을 사용할 수 있다.
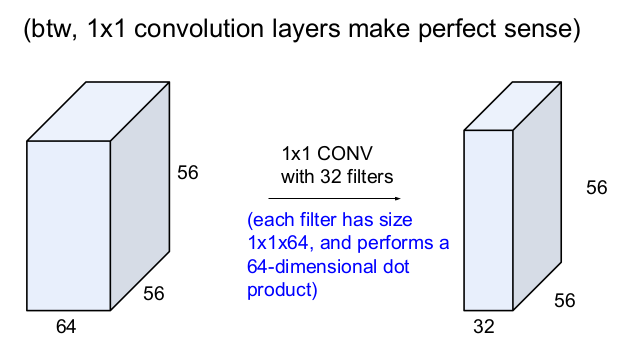
위의 그림은 56x56x64의 입력이미지에 32개의 1x1 conv 필터를 적용한다.
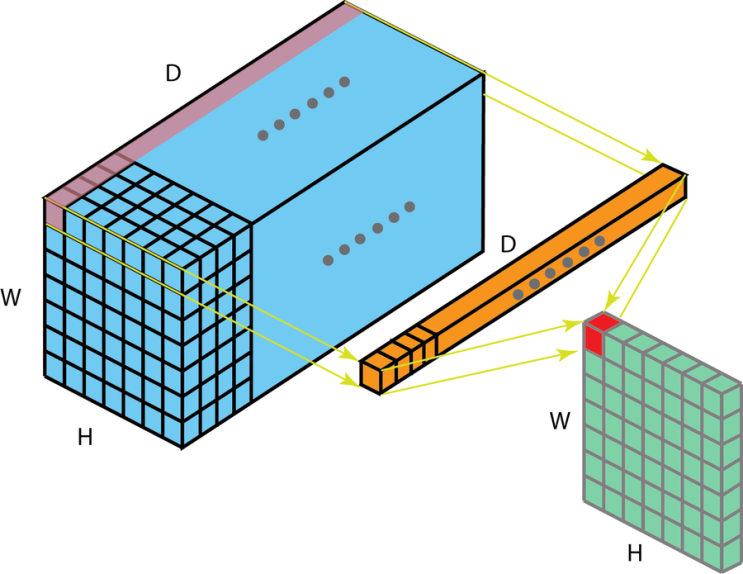
1x1 conv를 한다는 것은 1x1 만한 filter로 64개를 모두 내적한 다음 이것을 한 픽셀로 축소시킨다는 것이다.
즉 1x1 conv = 1x1x64 filter가 된다.
FC layer에서의 filter와 1x1 conv filter의 차이는 크기는 같을 수 있으나 FC layer는 고정된 크기를 입력이미지로 받지만, conv layer은 공간적으로 더 큰 입력 이미지를 받는다는 점이 다르다.
이것을 32번을 수행하므로 차원은 줄어들지 않는 56x56이고, 32개 필터이므로 56x56x32 가 output size가 된다.
1x1 convolution 은 depth를 줄여주는 역할을 한다.
위의 경우처럼 56x56x64 였던 이미지에 1x1 conv를 k개 필터를 적용한다면 output은 56x56xk가 된다.
Convolution layer Code
추가로
간단한 conv architecture을 가져와봤다.
1
2
3
4
5
6
7
8
9
10
11
# keras CNN
model = keras.Sequential([
keras.layers.Conv2D(32, kernel_size=(3,3), input_shape=(28,28,1), padding="same",activation=tf.nn.relu), # 32는 필터의 개수, kernel_size는 필터의 크기
keras.layers.MaxPool2D(pool_size(2,2), strides=(2,2), padding="same"), # (pool_size: 윈도우 크기, strides:윈도우가 움직이고자 하는 거리, padding:데이터가 없는 부분에 zero-padding)
keras.layers.Conv2D(64, kernel_size=(3,3), padding="same",activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size(2,2), strides=(2,2), padding="same"),
keras.layers.Flatten(),
keras.layers.Dense(1024, activation="relu")
keras.layers.Dense(10,activation="softmax")
keras.layers.Dropout(0.25)
])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# torch CNN
class CNN(nn.Module): # 마찬가지로 nn.module 클래스를 상속받는다.
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d( # 2차원 이미지 데이터를 nn.conv2d메서드를 이용해 convolution연산을 하는 filter
in_channels = 3, # filter의 크기는 상관없지만, 채널 수를 이미지의 채널 수와 동일하게 맞춰야 한다. 그래서 3으로 지정
out_channels = 8, # 설정해주는 filter개수만큼 depth가 정해진다. filter개수만큼 앞뒤로 쌓아 feature map을 형성하기 때문이다.
kernel_size = 3, # filter의 크기를 정하는 부분이다. 스칼라 값으로 설정하려면 가로*세로 크기인 filter을 이용해야 한다.
# 여기서 3x3 로 이용한다. 3x3 filter가 이미지 위를 9개의 픽셀 값과 filter 내에 있는 9개의 파라미터 값을 연산으로 진행
padding = 1) # 중앙에 비해 가장자리가 덜 연산되기에 테두리에 0을 채워 연산 횟수를 동일하게 맞춰주는 것
# 1로 설정하면 왼쪽에 1층, 오른쪽에 1층, 위 1층, 아래 1층으로 채움
self.conv2 = nn.Conv2d(in_channels = 8, # 앞에서 filter 수를 8로 했기에 입력을 8로 한다.
out_channels = 16, # depth를 16으로 지정
kernel_size = 3,
padding = 1)
self.pool = nn.MaxPool2d(kernel_size = 2, stride = 2) # convolution을 통해 feature map이 생성됐을 때, feture map을 부분적으로 이용한다.
# convolution을 통해 다양한 수치가 생성되기 때문이다. maxpool2d는 2차원의 feature map 내에서 가장 큰 값만 이용
self.fc1 = nn.Linear(8 * 8 * 16, 64) # convolution을 하는 이유는 이미지 내 픽셀과의 조합을 통한 특징을 추출
# feature map을 다양한 convolution을 통해 추출 후 1차원으로 펼친 후 여러 층의 fully connected layer를 통과시켜 분류
# 1차원으로 펼쳐도 이미 주변 정보를 반영한 결괏값으로 존재하기 때문에, 기존의 한계를 해결할 수 있다.
# 앞의 conv1,conv2 연산에서 feature map의 크기는 forward부분을 계산한 결과 8*8*16크기의 map이 된다.
# 즉 8*8의 2차원 데이터 16개가 겹쳐 있는 형태이다. 이를 1차원 데이터로 펼쳐 이용한다.
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 10) # 원핫인코딩으로 표현된 벡터 값과 loss를 계산해야 하므로 10으로 설정
def forward(self, x): # forward propagation을 정의
x = self.conv1(x)
x = F.relu(x) # convolution연산을 통해 생성된 feature map값에 비선형 함수 relu를 적용
x = self.pool(x) # maxpooling을 통해 생성된 feature map에 다운 샘플링을 적용한다.
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = x.view(-1, 8 * 8 * 16)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
x = F.log_softmax(x)
return x
