
- 3강 리뷰
1) hinge loss
2) loss function에 대해 SVM loss, softmax loss
3) 최적의 loss를 갖게 하는 파라미터 w를 찾기위해 optimization - gradient descent와 Stochastic gradient descent
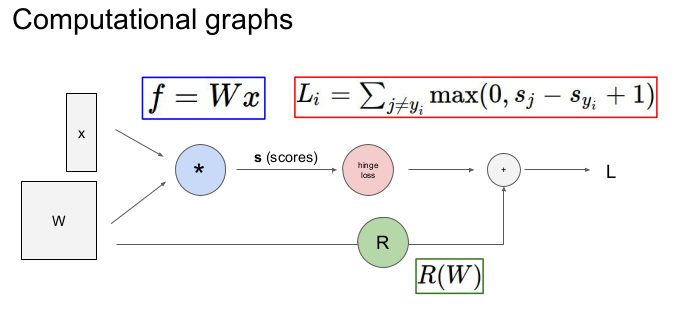
위의 그림은 computational graph라고 부른다. 총 loss를 구하는 linear classifier 과정을 나타낸 것으로, (f= xW)를 통해 score를 구하고, s로부터 hinge loss를 통해 구한 Li 와, W로부터 구한 R(regularization term)을 더해 총 loss를 더한다.
Backpropagation(역전파)
이 computational graph를 통해 gradient를 구해보자.
각 parameter에 대한 편미분 값을 얻어 경사하강법을 진행할 것이다.
먼저 computational graph에 순차적으로 값을 집어넣어 함수 값을 구한다.(forward)
그 후 역방향으로 차례대로 미분하여 gradient를 구하는데, 이를 backpropagation이라 부른다.(backward)
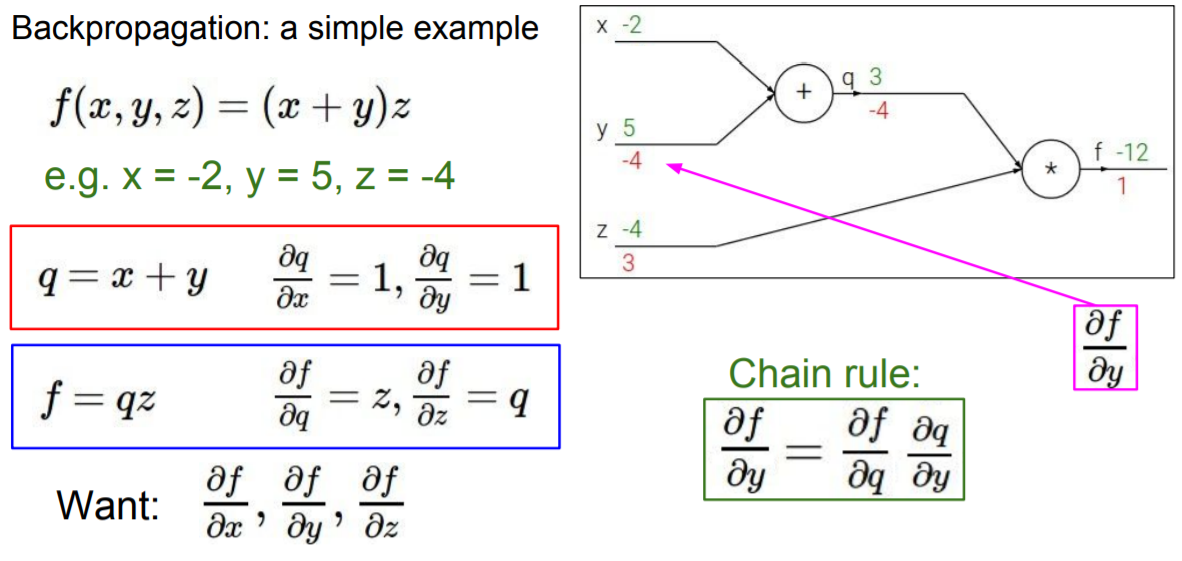
backpropagation :
- 구하고자 하는 gradient는 x,y,z 각각에 대한 f의 gradient
- f의 미분값을 global gradient라고 부르고, node에 위치한 것의 미분값은 local gradient라 부른다.
- 전체 과정을 chain rule을 이용하여 역계산
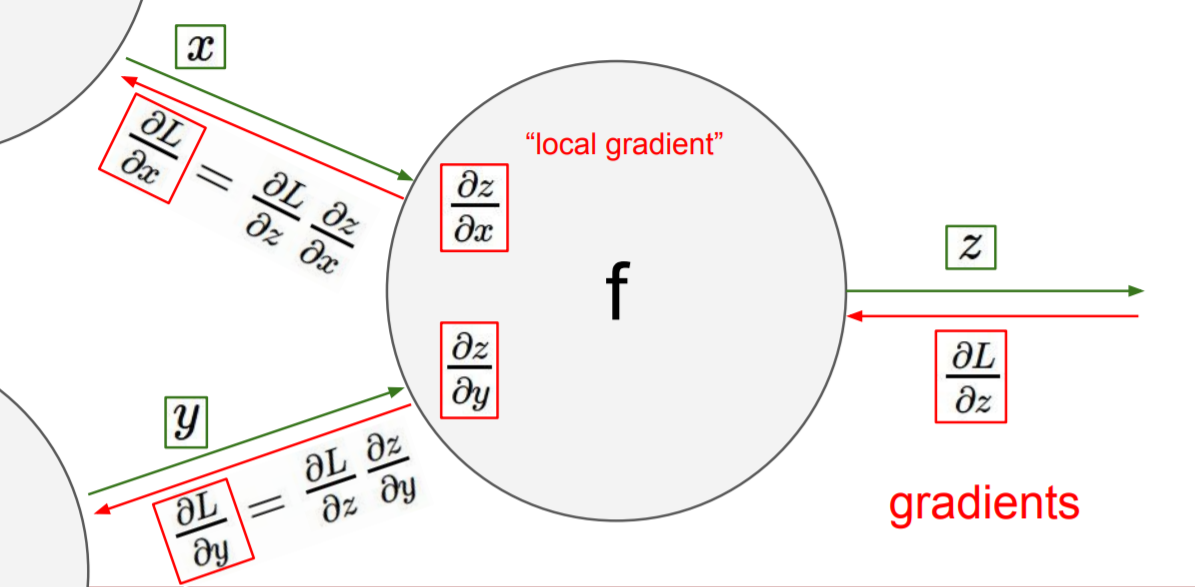
각 local gradient는 편미분을 통해 계산한다. 그 후에 x,y는 f와 바로 연결되어 있지 않고, q와 연결되어 있으므로 chain rule을 이용하여 원하는 값을 구한다.
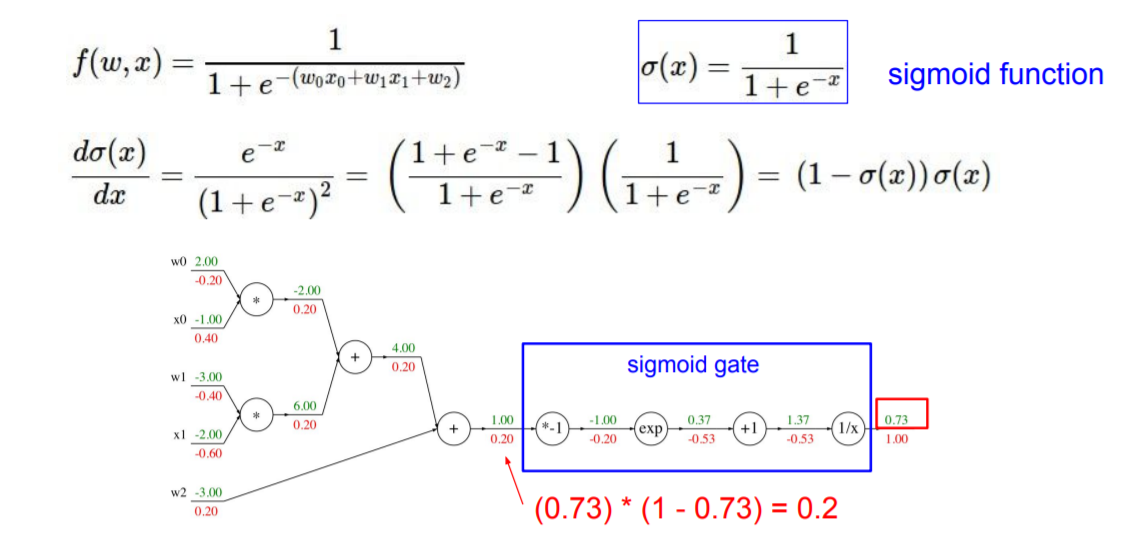
이 경우 w,x에 대한 함수 f는 1/ e^ - (w0x0 + w1x1 + w2) 이다.
이 graph는 f를 계산하는데 사용되는 일련의 과정을 node로 그려놓은 것이다.
backpropagation을 하기 위해서는 뒤에서부터 시작하게 될 것이다. 최종 변수에 대한 출력의 gradient는 1이다. (df/df =1)
한 단계 뒤로 가서 1/x 이전의 input에 대한 gradient를 살펴보기 위해 1/x를 x에 대해 미분한다. 그 후 x 값을 집어넣고 chain rule을 적용하면 -0.53을 구할 수 있다.
그 후 input + 1 = output 이므로 output을 fc(x)라 했을 때 df/dx = 1 이다. 따라서 gradient는 -0.53
sigmoid처럼 식을 나누지 않고 미분해도 복잡하지 않은 경우 묶어서 생각해볼 수도 있다.
pattern in backward flow
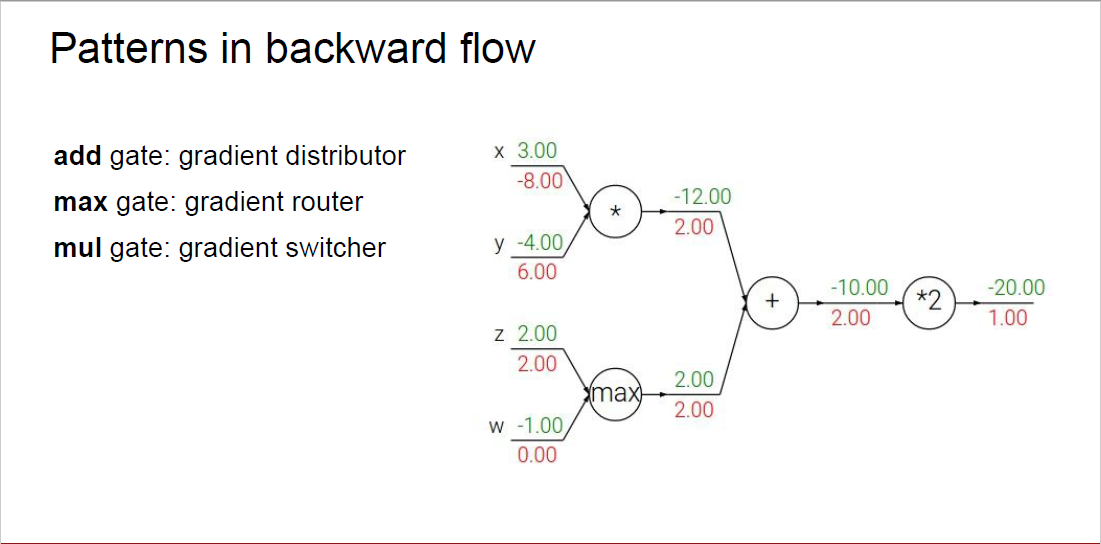

- add gate: 입력되는 기울기를 그대로 출력값으로 전파해준다.(local gradient가 항상 1)(gradient distributor)
- max gate: z와 x 중 큰 값에만 gradient를 그대로 출력하고, 나머지는 0이 된다.(gradient router)
- mul gate: 반대편의 값을 들어오는 기울기와 곱해주면 된다.(32=6, -42=8) (gradient switcher)
- branches: 두 가닥에서 넘어노느 gradient를 받는 경우 그냥 더해준다.
gradients for vector
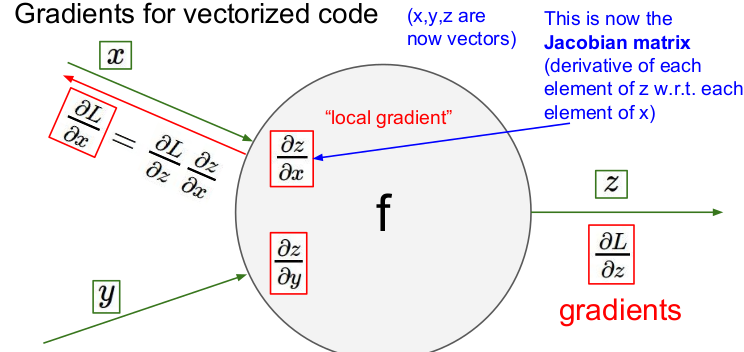
변수 x,y,z 에서 숫자대신 벡터를 넣는다고 하자. 모든 흐름은 똑같다. 차이점은 gradient를 구할 때 야코비안 행렬(jacobian matrix)을 사용하는 것이다. 야코비안 행렬의 각 행은 입력값에 대한 출력의 편미분으로 이루어져 있다.
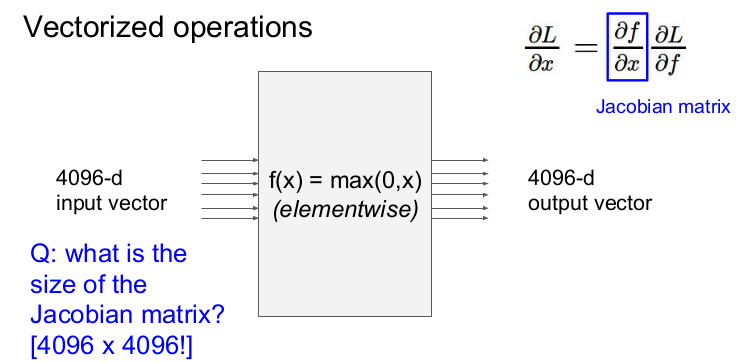
입력값과 출력값이 4096차원 벡터면 야코비안 행렬의 크기는 4096x4096이 된다.
minibatch를 사용하므로 총 409,600x409,600 의 행렬이 된다. 이는 너무 커서 작업에 실용적이지 않다. 실제로는 이 거대한 jacobian을 계산할 필요가 없다.
jacobian 행렬은 대각 행렬의 형태를 띄고 있다. 다만 1만 존재하는 것이 아닌 0과 1이 섞여 있을 뿐이다.
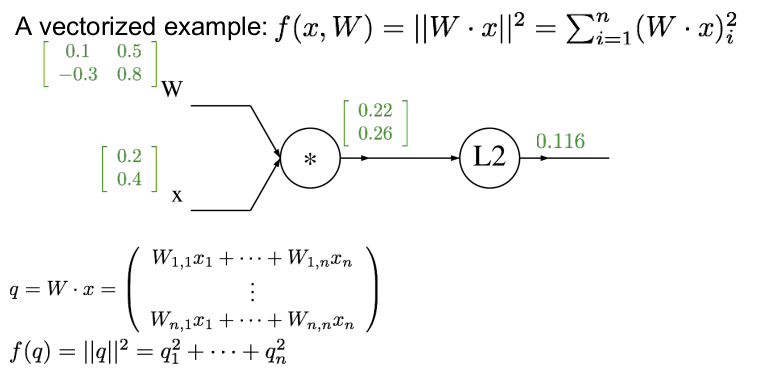
위와 같이 forward pass하여 각각의 gate의 값을 구한다. 각 게이트의 값은 행렬곱하면 구할 수 있다.
w는 2x2행렬이고 x는 2차원의 벡터이다.
q는 w*x인데,f를 q에 대한 표현으로 나타내려고 하는데, 이는 q의 L2 norm과 같이 q1의 제곱과 q2의 제곱을 합친 것과 같다. 이런 방식으로 q를 통해 f를 구한다.
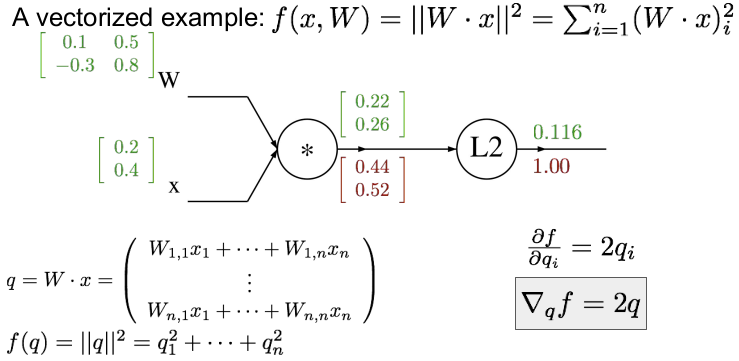
출력 node에서의 gradient는 항상 1이다.
backpropagation을 하는데, L2 이전의 중간 변수인 q에 대한 gradient를 구하고자 한다.
q는 2차원의 벡터이고, 우리가 찾고 싶은 것은 q의 각각의 요소가 f의 최종 값에 어떤 영향을 미치는지다.
qi에 대한 f의 gradient는 2qi가 된다. 왜냐하면 f는 q^2이기 떄문이다.
이를 벡터의 형태로 ∇qf 로 나타낼 수 있다. 2q를 통해 [0.44 0.52]를 얻을 수 있다.
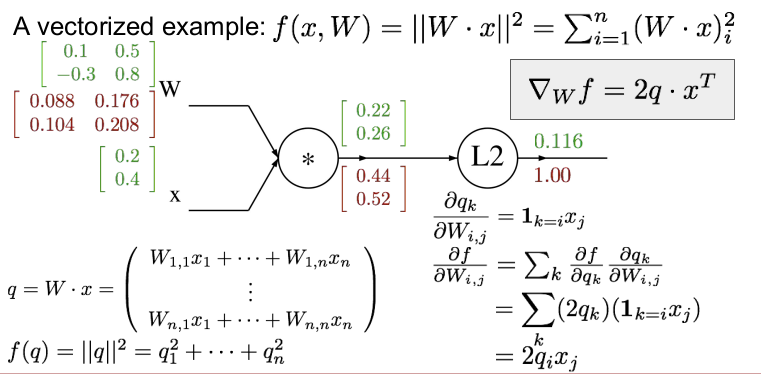
이 후, w의 gradient를 구할 것이다.
여기서 chain rule을 사용한다. w에 대한 q의 local gradient를 계산하려면 요소별 연산을 다시 해야 한다. 각각의 q에 대한 영향을 보자.
w의 각 요소에 대한 q의 각 요소를 계산하기 위해 jacobian을 사용한다.
q = W*x이다. q의 첫번째 요소의 gradient는 wji에서 w11에 대한 q1이다. 이는 x1에 해당한다.
w에 대한 f의 gradient를 xj와 wi,j에 대한 qk의 식으로 일반화 할 수 있다.
qk에 대한 f의 미분을 합성할 때 df/dqk * dqk/dwij 로 표현가능하다. 이전에 계산한 것과 같이 df/dqk = 2qk 이고, wij에 대한 qk의 gradient는 xj* 1(k=i이면) 가 된다.
따라서 2qixj가 된다.
유도한 식을 벡터화된 형식으로 작성하면 ∇wf = 2q*x^T 가 된다.
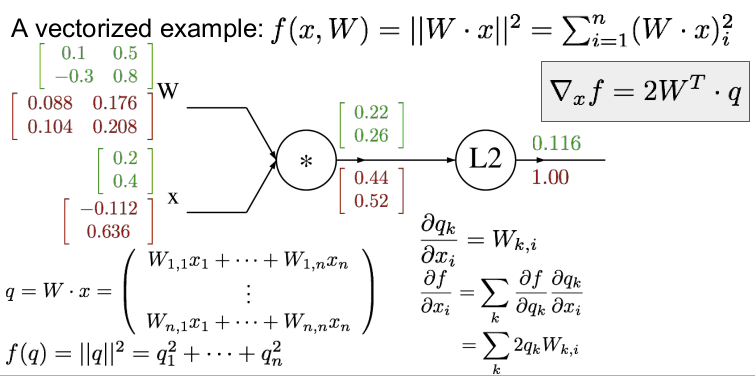
이제 xi에 대한 qk를 구할 것이다.
dqk / dxi = wki 와 같다. 그 후 chain rule을 사용하여 df/dqk와 dqk/dxi 로 표현하고, df/dqk = 2qk, dqk/dxi=Wk,i 이다.
이를 벡터화하면 ∇xf = 2W^T * q, 즉 ∇wf에서 w를 x로 바꾼 것과 같다.
아래는 forward pass, backward pass의 API를 이용하여 sigmoid 함수를 포함한 함수의 역전파를 구현한 것이다. 위에서는 forward를 구현하고, 그것을 이용해 backward를 구현했다.
forward pass에서는 노드의 출력을 계산하고, backward pass에서는 gradient를 계산한다.
1
2
3
4
5
6
7
8
9
10
11
class ComputationalGraph(object):
def forward(inputs):
# 1. [pass inputs to input gates]
# 2. forward the computational graph
for gate in self.graph.nodes_topologically_sorted():
gate.forward()
return loss # the final gate in the graph outputs the loss
def backward():
for gate in reversed(Self.graph.nodes_topologically_sorted()):
gate.backward() # little piece of backpropagation (chain rull applied)
return inputs_gradients

x,y,z가 스칼라일 떄, x,y를 입력으로 받고 z를 리턴하는 computational graph를 구현한 것이다.
backward로 진행할 때는 입력으로 dz를 받고 출력으로 입력인 x,y의 gradient인 dx,dy를 출력한다.
- Summary
- neural nets will be very large: impractical to write down gradient formula by hand for all parameters
- backpropagation = recursive application of the chain rule along a computational graph to compute the gradients of all inputs/parameters/intermediates
- implementations maintain a graph structure, where the nodes implement the forward() / backward() API
- forward: compute result of an operation and save any intermediates needed for gradient computation in memory
- backward: apply the chain rule to compute the gradient of the loss function with respect to the inputs
Neural Networks
이제까지는 선형함수 f=W*x만을 다뤘다. 이제는 n-layer Neural Network를 다루고자 한다. n층 신경망은 비선형함수인 활성함수(activation function)을 사용한다.
2층 신경망에서는 활성함수인 max함수로 ReLU를 사용한다.
2-layer Neural Network로서의 f는 W2max(0,W1x) 로 표현가능하다. 즉, w1 과 x를 행렬 곱한 것에 대한 max를 취하고 W2를 곱해준다.
max(w1 * x)를 h라 할 때,
h는 w1에서 나오는 score 값인데, 이 score 값을 h에 입력하므로 h의 input data는 w1의 score가 될 것이다. 마찬가지로 w2는 h의 score가 된다.
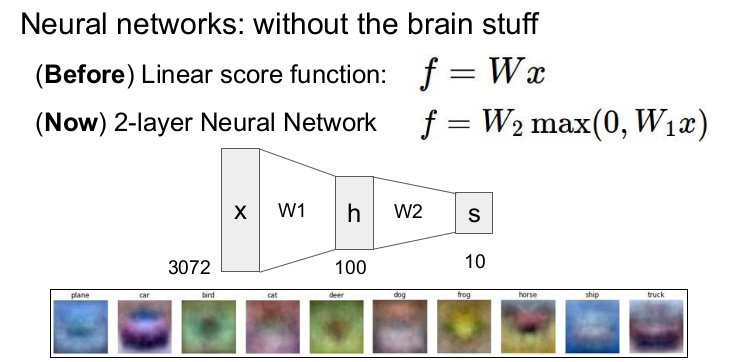
이때, h를 hidden layer이라 한다. 입력층과 출력층 사이의 모든 층을 가르킨다.
2층 신경망을 간단히 코드화하면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import numpy as np
from numpy.random import randn
# N: Class number, D_in: input행에 들어오는 입력 행렬 size, H:hidden size, D_out: output size
N, D_in, H, D_out = 64, 1000, 100, 10
x, y = randn(N, D_in), randn(N, D_out) # x,y는 random input data로, randn은 정규 분포에서 matrix array를 생성하는 함수
w1, w2 = randn(D_in, H), randn(H, D_out)
for t in range(2000):
h = 1/(1+np.exp(-x.dot(w1)))
y_pred = h.dot(w2)
loss = np.square(y_pred - y).sum()
print(t, loss)
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h.T.dot(grad_y_pred)
grad_h = grad_y_pred.dot(w2.T)
grad_w1 = x.T.dot(grad_h * h * (1-h))
w1 -= 1e-4 * grad_w1
w2 -= 1e-4 * grad_w2
인간의 뇌에 있는 뉴런을 그림으로 표현하면 아래와 같다.
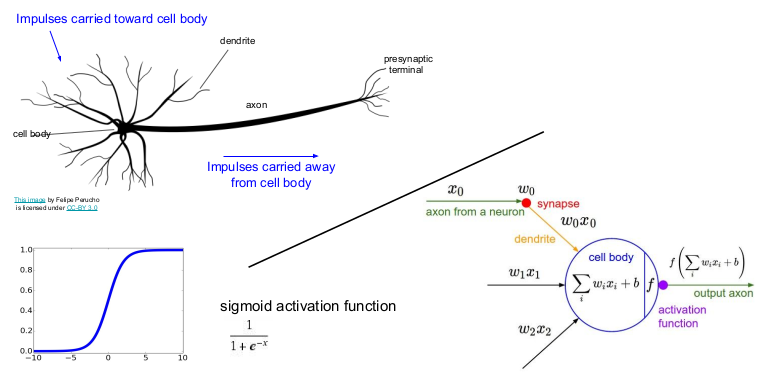
수상돌기에서 신호를 받으면 세포체에서 신호를 종합해서 다른 뉴런으로 신호를 전달시킨다.
이는 각 computational node가 하는 일과 비슷하다.
입력값(신호)인 x0,x1,x2가 들어오면 세포체(함수)에서 가중치w와 입력값x를 더한 값을 서로 결합하고, 활성함수에 의해 비선형 함수로 만든 후 다음 노드에 전달한다.
뉴런의 형태를 코드로 구현하면 아래와 같다.
1
2
3
4
5
6
class Neuron:
def neuron_tick(inputs):
'''assum inputs and weights are 1-D nunpy arrays and bias is a number'''
cell_body_sum = np.sum(inputs * self.weights) + self.bias
firing_rate = 1.0 / (1.0 + math.exp(-cell_body_sum)) # sigmoid activation function
return firing_rate
사용 가능한 활성함수가 다양하게 존재한다.
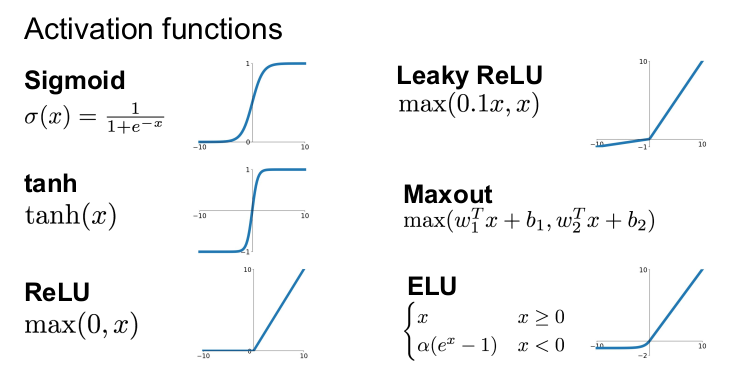
실제 뉴런과 가장 비슷한 활성함수가 ReLU라고 하기도 한다. 모든 음수 입력값에 대해서는 0, 양수 입력에 대해서는 선형 함수 형태이다.
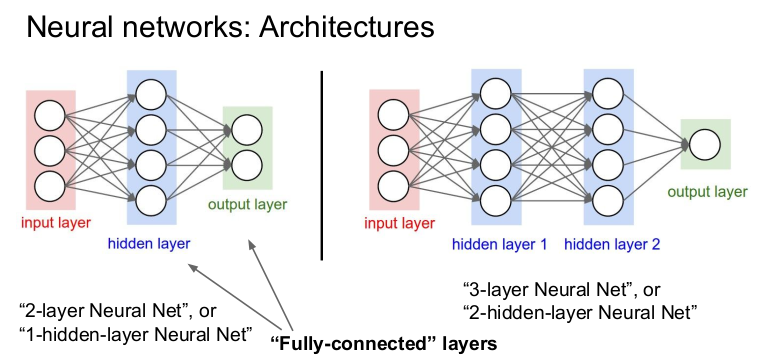
신경망의 architecture를 그림으로 표현했다. 각 노드가 모두 연결된 fully-connected(FC) layer 형태다.
위의 뉴런 함수를 본 따 신경망 코드를 구축했다.
1
2
3
4
5
6
# forward pass of 3-layer neural network
f = lambda x: 1.0/(1.0+np.exp(-x)) # activation function
x = np.random.randn(3,1) # random input vector (3x1)
h1 = f(np.dot(W1,x) + b1) # calculate first hidden layer (4x1)
h2 = f(np.dot(W2,h1)+ b2) # calculate second hidden layer (4x1)
output = np.dot(W3,h2) + b3 # output (1x1)
