
Train Custom Data
https://github.com/ultralytics/yolov5/blob/master/tutorial.ipynb
Prepare start
시작 전 환경 설정을 위해 repogitory 를 clone 하고, requiements.txt를 설치한다.
1
2
3
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
Train on Custom Data
- COCO128 Dataset 을 사용할 것이다. 이는 총 128개의 class를 포함하고 있다.
data/coco128.yaml 은 path 를 통해 dataset root 를 설정, train/val/test image directories(txt file about image paths) 설정, number of classes , nc와 class names 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 80 # number of classes
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ] # class names
- Create Labels
CVAT 나 makesense.ai 에서 툴을 사용하여 coco set 에서 yolo format 으로 변환시켜줘야 한다.
- Organize Directories

yolov5/data directory에 image 와 label 폴더를 만들고, 그 안에 각각 train 과 val 폴더를 더 만든다.
그리고 다운받은 coco 파일들을 image와 label을 train 과 val에 적절히 분리하여 넣는다.
- Select a Model
yolov5 의 4가지 종류 중 적절한 모델을 선택한다. s의 경우 가장 작고, 빠르다.
- train
coco128.yaml, yolov5.pt 파일을 사용하여 yolov5s 모델을 훈련시킨다.
coco128.yaml의 경우 이미지와 라벨을 yolo format으로 변환해야 작동된다.
yolov5.pt는 미리 훈련된 pretrained weights 이다.
1
2
# Train YOLOv5s on COCO128 for 3 epochs
$ python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
–cache 는 무엇인가
Inference
weights = yolov5s.pt
conf = confidence를 나타내는 값이다.
source = data/images/
1
!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images/Image(filename='runs/detect/exp/zidane.jpg', width=600)
Validate
Coco val2017 dataset 을 활용하여 테스트를 해본다.
data 는 coco.yaml
weights 는 yolov5.pt
iou 는 0.65
1
2
3
4
5
6
7
8
# Download COCO val2017
torch.hub.download_url_to_file('https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017val.zip', 'tmp.zip')
!unzip -q tmp.zip -d ../datasets && rm tmp.zip
# Run YOLOv5x on COCO val2017
!python val.py --weights yolov5x.pt --data coco.yaml --img 640 --iou 0.65 --half
half 는 device의 한 종류로 half가 있다면 cpu 대신 사용할 수 있다.
Test
coco test2017 dataset을 다운받아 실행한다.
1
2
3
4
5
6
7
8
# Download COCO test-dev2017
torch.hub.download_url_to_file('https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels.zip', 'tmp.zip')
!unzip -q tmp.zip -d ../ && rm tmp.zip # unzip labels
!f="test2017.zip" && curl http://images.cocodataset.org/zips/$f -o $f && unzip -q $f && rm $f # 7GB, 41k images
%mv ./test2017 ../coco/images # move to /coco
# Run YOLOv5s on COCO test-dev2017 using --task test
!python val.py --weights yolov5s.pt --data coco.yaml --task test
Load From Pytorch Hub
📚 여기서는 Pytorch Hub(https://pytorch.org/hub/ultralytics_yolov5) 에서 yolov5 🚀 를 불러오는 방법에 대해 설명한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import cv2
import torch
from PIL import Image
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Images
for f in ['zidane.jpg', 'bus.jpg']:
torch.hub.download_url_to_file('https://ultralytics.com/images/' + f, f) # download 2 images
img1 = Image.open('zidane.jpg') # PIL image
img2 = cv2.imread('bus.jpg')[..., ::-1] # OpenCV image (BGR to RGB)
imgs = [img1, img2] # batch of images
# Inference
results = model(imgs, size=640) # includes NMS
# Results
results.print()
results.save() # or .show()
results.xyxy[0] # img1 predictions (tensor)
results.pandas().xyxy[0] # img1 predictions (pandas)
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
## default Model 전체 architecture
class AutoShape(nn.Module):
# YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
conf = 0.25 # NMS confidence threshold
iou = 0.45 # NMS IoU threshold
classes = None # (optional list) filter by class
max_det = 1000 # maximum number of detections per image
def __init__(self, model):
super().__init__()
self.model = model.eval()
def autoshape(self):
LOGGER.info('AutoShape already enabled, skipping... ') # model already converted to model.autoshape()
return self
@torch.no_grad()
def forward(self, imgs, size=640, augment=False, profile=False):
# Inference from various sources. For height=640, width=1280, RGB images example inputs are:
# file: imgs = 'data/images/zidane.jpg' # str or PosixPath
# URI: = 'https://ultralytics.com/images/zidane.jpg'
# OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
# PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
# numpy: = np.zeros((640,1280,3)) # HWC
# torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
# multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
default model을 분석해보자.
inference 를 위한 hyperparameters setting 을 한다.
1
2
3
4
5
model.conf = 0.25 # confidence threshold (0-1)
model.iou = 0.45 # NMS IoU threshold (0-1)
model.classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for persons, cats and dogs
results = model(imgs, size=320) # custom inference size
input channel
pretrained yolov5 model 의 input channel=4 로 변경하려면
1
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)
이 경우, pretrained output layers과 일치하지 않는 output layers 를 제외한 pretrained weights 로 구성되어 있다. output layers는 ramdom weights 로 초기화 된다.
number of classes
또, nc, number of classes=10으로 설정하려면
1
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)
이 경우에도 마찬가지로, pretrained output layers과 일치하지 않는 output layers 를 제외한 pretrained weights 로 구성되어 있다. output layers는 ramdom weights 로 초기화 된다.
force reload
위의 두 가지 방법에서 문제가 생긴다면 force_reload=True 를 통해 기존 캐시를 삭제하고 pytorch hub에서 최신 yolov5 버전을 새로 다운할 수 있다.
1
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload
screenshot
desktop screenshot 에서 inference 를 하려면
1
2
3
4
5
6
7
8
9
10
11
import torch
from PIL import ImageGrab
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Image
img = ImageGrab.grab() # take the screenshot
# Inference
results = model(img)
Training
inference 가 아닌 training 에서 yolov5를 불러올 때는, autoshape=False 하는 것이 좋다. 초기 weights를 랜덤하게 설정하고 싶다면 pretrained=False 해야 한다.
1
2
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch
Base64 Results
API service로 결과를 얻기 위해서는 Flask REST API 또는 #2291 를 참고해라. 아래는 그에 대한 예시로 Bask64를 사용하는 방법을 가져왔다.
1
2
3
4
5
6
7
8
9
results = model(imgs) # inference
results.imgs # array of original images (as np array) passed to model for inference
results.render() # updates results.imgs with boxes and labels
for img in results.imgs:
buffered = BytesIO()
img_base64 = Image.fromarray(img)
img_base64.save(buffered, format="JPEG")
print(base64.b64encode(buffered.getvalue()).decode('utf-8')) # base64 encoded image with results
JSON Results
JSON 형태로 출력하고자 한다면 to_json() 방법을 활용한 .pandas() 를 사용해야 한다. orient 인수를 활용하여 json 형식을 수정할 수 있다.
1
2
3
results = model(imgs) # inference
results.pandas().xyxy[0].to_json(orient="records") # JSON img1 predictions
other models
yolov5s.pt 대신에 custom VOC-trained Yolov5 model 인 best.pt를 불러와 사용할 수도 있다.
1
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt') # default
export ONNX, TorchScript, CoreML
📚 여기서는 Pytorch 에서 ONNX 나 TorchScript 로 YOLOv5 🚀 를 추출하는 방법을 설명한다.
export.py를 사용하면 ONNX, TorchScript, CoreML 등으로도 추출할 수 있다.
1
python export.py --weights yolov5s.pt --img 640 --batch 1 # export at 640x640 with batch size 1
[Test-Time Augmentation]
📚 여기서는 test나 inference 동안 mAP 와 recall(재현율) 을 향상시키는 TTA(test Time Augmentaion) 을 사용하는 방법을 설명한다.
val.py 에 명령을 추가하여 TTA를 사용하도록 설정하고, 향상된 결과를 위해 이미지 크기를 약 30% 늘린다.
TTA를 활성화된 상태에서 inference 하면 일반적으로 image 가 3개의 다른 해상도로 처리되고, NMS 이전에 출력이 병합되기 때문에 시간이 2~3배정도 더 소요된다.
1
$ python val.py --weights yolov5x.pt --data coco.yaml --img 832 --augment --half
inference with TTA
detect.py 를 활용한 TTA inference 는 val.py TTA 와 동일하게 --augment 를 설정한다.
Pytorch Hub TTA
pytorch Hub 에서 TTA 는 자동으로 통합되어 있다. inference 시에 augment=True 를 입력시키면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom
# Images
img = 'https://ultralytics.com/images/zidane.jpg' # or file, PIL, OpenCV, numpy, multiple
# Inference
results = model(img, augment=True) # <--- TTA inference
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
Customize
models/yolo.py 에서 forward_augment()를 수정하여 TTA를 customize 할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
def forward_augment(self, x):
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self.forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
return torch.cat(y, 1), None # augmented inference, train
Model Ensembling
📚 여기서는 test 나 inference 동안 mAP 와 recall 을 향상시키기 위해서 ensembling을 YOLOv5 🚀 모델에 사용하는 방법을 설명한다.
From https://www.sciencedirect.com/topics/computer-science/ensemble-modeling:
앙상블 모델링은 다양한 모델링 알고리즘을 사용하거나 다른 교육 데이터 세트를 사용하여 결과를 예측하기 위해 여러 다양한 모델을 생성하는 프로세스입니다. 그런 다음 앙상블 모델은 각 기본 모델의 예측을 집계하고 보이지 않는 데이터에 대해 최종 예측을 한 번 수행합니다. 앙상블 모델을 사용하는 동기는 예측의 일반화 오류를 줄이기 위한 것입니다.
기본 모형이 다양하고 독립적인 경우 앙상블 접근 방식을 사용할 때 모형의 예측 오차는 감소합니다. 그 접근법은 예측을 할 때 군중의 지혜를 추구한다. 앙상블 모델은 모델 내에 여러 기본 모델이 있지만 단일 모델로 작동 및 수행됩니다.
Ensembling Test
test 나 inference 시에 --weights 에 다른 모델을 추가함으로써 ensembling 하여 평가할 수 있다.
1
python val.py --weights yolov5x.pt yolov5l6.pt --data coco.yaml --img 640 --half
Ensembling Inference
inference 시에도 동일하게 --weights에 두 개를 입력시키면 된다.
1
python detect.py --weights yolov5x.pt yolov5l6.pt --img 640 --source data/images
Pruning / Sparsity
📚 여기서는 YOLOv5 🚀 모델에 pruning 을 적용하는 방법을 설명한다.
- Pruning
torch_utils.prune() 을 이용하여 pruned model 을 test에 적용할 수 있다. val.py 에 아래의 코드를 입력하여 업데이트 하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
# Half
#-------- 추가 --------
# Prune
from utils.torch_utils import prune
prune(model, 0.3)
#----------------------
# configure
model.eval()
30% pruned output:
1
2
3
4
5
...
Fusing layers...
Model Summary: 476 layers, 87730285 parameters, 0 gradients
Pruning model... 0.3 global sparsity
...
output 을 통해 pruning 후 모델에서 30%의 sparsity 를 달성했다는 것을 볼 수 있다. 이는 layer이 0인 nn.conv2d 의 weights parameter 가 30% 만 수행했다는 뜻이다.
inference 시간은 바뀌지 않으나, model의 AP 와 AP scores 은 감소했다.
Hyperparameter Evolution
📚 여기서는 YOLOv5 🚀 의 hyperparameter evolution 을 설명한다. hyperparameter evolution 이란 optimization 을 위해 GA(genetic algorithm) 을 사용한 hyperparameter optimization 의 한 종류이다.
ML control 의 Hyperparameters 은 최적의 값을 찾는 것이 어렵다. grid search와 같은 전통적인 방법은 1) 높은 차원, 2) 차원 간의 불확실한 상관관계, 3) 각 지점에서 적합성을 평가하는 비용이 너무 많이 발생 함으로써 빠르게 다루기 어렵다. 그래서 GA가 hyperparameter 검색에 적합한 후보가 될 수 있다.
Install Hyperparameter
yolov5 는 train 에 사용되는 hyperparameter이 30개 정도 사용된다. 이것들은 /data directory 에서 확인할 수 있다. 처음의 좋은 시작은 더 나은 결과를 만든다. 애매하다면, yolov5 coco training 의 parameter을 사용하는 것이 좋다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# yolov5/data/hyps/hyp.scratch.yaml
# Hyperparameters for COCO training from scratch
# python train.py --batch 40 --cfg yolov5m.yaml --weights '' --data coco.yaml --img 640 --epochs 300
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
Define Fitness
fitness는 우리가 최대한 활용하고자 하는 값이다. yolov5에서 우리는 mAP@0.5(weight의 10%) 와 mAP@0.5:0.95(90%를 남김) 과 같은 가중치 결합의 default fitness를 가지고 있다.
1
2
3
4
5
# yolov5/utils/metrics.py
def fitness(x):
# Model fitness as a weighted combination of metrics
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
return (x[:, :4] * w).sum(1)
Evolve
이 예제에서 base scenario 는 사전 훈련된 yolov5s 를 사용하여 COCO128 을 10 epochs 동안 finetuning 한다.
--evolve 를 통해 epoch을 진행하면서 hyperparameter을 최적화한다.
1
2
3
4
5
6
7
# single-GPU
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
# Multi-GPU
for i in 0 1 2 3; do
nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve --device $i > evolve_gpu_$i.log &
done
--evolve 는 기본적으로 300번을 반복하면서 hyperparamemter를 최적화하지만, --evolve 1000 과 같이 작성하면 1000번 반복으로 변경할 수 있다. 반복하면서 가장 최적의 parameter를 runs/evolve/hyp_evolved.yaml 에 저장한다.
최소한 300번은 해야 좋은 결과를 얻을 수 있다고 한다. 또, evolution 자체도 일반적으로 시간이 오래 걸리고 비싼데, 수천번의 반복을 하게 되면 많은 양의 GPU를 사용하게 될 것이다.
Transfer Learning with Frozen Layers
📚 여기서는 transfer learning 시에 Yolov5 🚀 layer 를 frozen 시키는 방법을 설명한다. transfer learning 은 새로운 data에 대한 model을 빠르게 구축할 수 있다. 일부 initial weights 를 고정시키고, 나머지 weights 는 loss를 계산하는데 사용되고, optimizer에 의해 업데이트된다. 이는 원래보다 훨씬 적은 비용이 든다. 정확도는 다소 떨어질 수 있으나, training time 을 단축시킬 수 있다.
Before start
1
2
3
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt wandb # add W&B for logging
Frozen Backbone
train.py 와 동일한 architecture 를 사용하려는 부분은 training 시작 전에 grad=False 로 설정하면 frozen된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# yolov5/train.py
# Freeze
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f'freezing {k}')
v.requires_grad = False
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
for k, v in model.named_parameters():
print(k)
# Output
model.0.conv.conv.weight
model.0.conv.bn.weight
model.0.conv.bn.bias
model.1.conv.weight
model.1.bn.weight
model.1.bn.bias
model.2.cv1.conv.weight
model.2.cv1.bn.weight
...
model.23.m.0.cv2.bn.weight
model.23.m.0.cv2.bn.bias
model.24.m.0.weight
model.24.m.0.bias
model.24.m.1.weight
model.24.m.1.bias
model.24.m.2.weight
model.24.m.2.bias
yolov5 에서 backbone 은 0~9 layer에 해당하므로 backbone 고정을 위해 9 layer 까지 freeze 한다.
1
python train.py --freeze 10
모든 layer을 고정하기 위해서는 아래와 같이 입력하면 된다.
1
python train.py --freeze 24
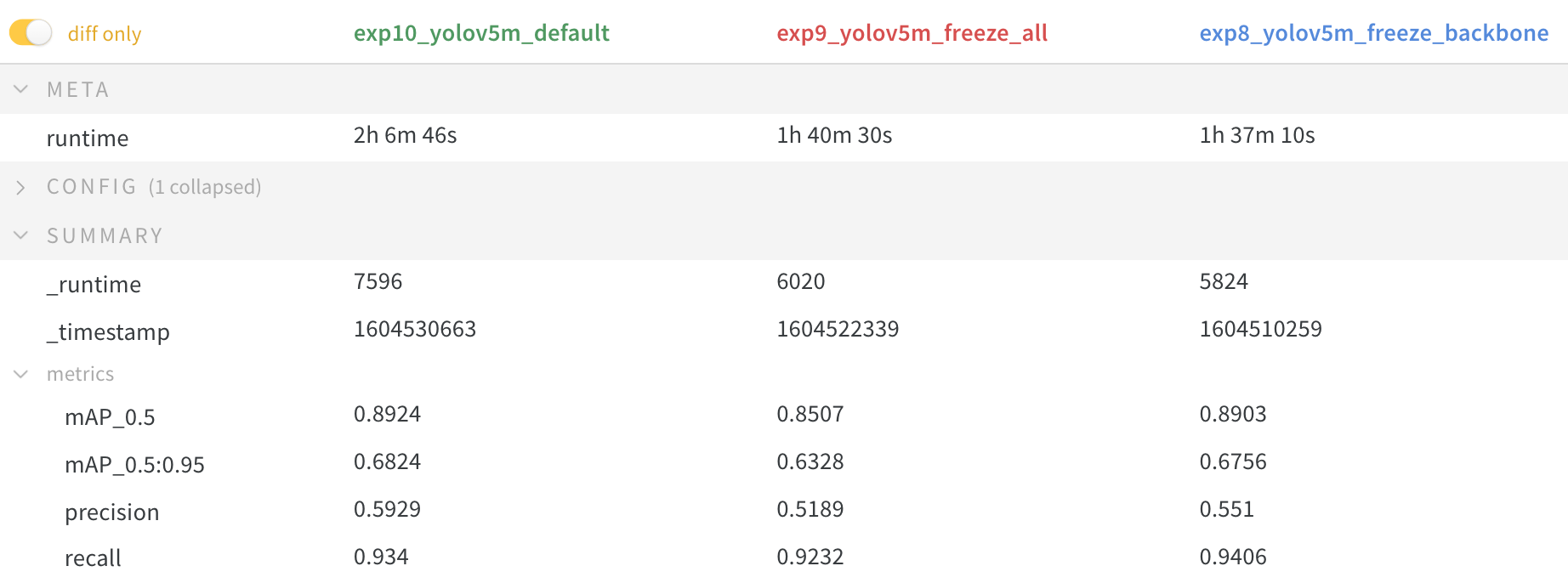
모든 layer freeze 시 정확도가 떨어지고, backbone만 freeze 해도 일반적인 모델보다 떨어지지만, 속도가 빨라지고, 메모리 사용량도 줄어든다.
- Appendix
repo 기능을 검증하여 테스트한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
###### Reproduce
for x in 'yolov5s', 'yolov5m', 'yolov5l', 'yolov5x':
!python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.25 --iou 0.45 # speed
!python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.001 --iou 0.65 # mAP
###### Unit tests
%%shell
export PYTHONPATH="$PWD" # to run *.py. files in subdirectories
rm -rf runs # remove runs/
for m in yolov5s; do # models
python train.py --weights $m.pt --epochs 3 --img 320 --device 0 # train pretrained
python train.py --weights '' --cfg $m.yaml --epochs 3 --img 320 --device 0 # train scratch
for d in 0 cpu; do # devices
python detect.py --weights $m.pt --device $d # detect official
python detect.py --weights runs/train/exp/weights/best.pt --device $d # detect custom
python val.py --weights $m.pt --device $d # val official
python val.py --weights runs/train/exp/weights/best.pt --device $d # val custom
done
python hubconf.py # hub
python models/yolo.py --cfg $m.yaml # inspect
python export.py --weights $m.pt --img 640 --batch 1 # export
done
###### Profile
from utils.torch_utils import profile
m1 = lambda x: x * torch.sigmoid(x)
m2 = torch.nn.SiLU()
results = profile(input=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=100)
###### Evolve
!python train.py --img 640 --batch 64 --epochs 100 --data coco128.yaml --weights yolov5s.pt --cache --noautoanchor --evolve
!d=runs/train/evolve && cp evolve.* $d && zip -r evolve.zip $d && gsutil mv evolve.zip gs://bucket # upload results (optional)
### VOC
for b, m in zip([64, 48, 32, 16], ['yolov5s', 'yolov5m', 'yolov5l', 'yolov5x']): # zip(batch_size, model)
!python train.py --batch {b} --weights {m}.pt --data VOC.yaml --epochs 50 --cache --img 512 --nosave --hyp hyp.finetune.yaml --project VOC --name {m}
reference
- “yolov5 github tutorial” - https://colab.research.google.com/drive/1uFK2FT-0c3rmrUoJoKq8QVcKCsbdwxRb
- “빵형 YOLOV5 train Mask” - https://colab.research.google.com/drive/1E8lRvkLVWs9vijUI1S7febGSQ2eb6hzm#scrollTo=9EflbG16Zt21
- “How to train YOLOv5 on a custom dataset code - roboflow” - https://colab.research.google.com/drive/1gDZ2xcTOgR39tGGs-EZ6i3RTs16wmzZQ#scrollTo=GD9gUQpaBxNa
- “YOLOV5 Mask Wearing Dataset - roboflow” - https://public.roboflow.com/object-detection/mask-wearing
- “YOLOV5 fake or real - kaggle” - https://www.kaggle.com/orkatz2/yolov5-fake-or-real-single-model-l-b-0-753?scriptVersionId=37672232
