

YOLO review
입력된 이미지는 low-level feature 에서 high-level feature가 되고, classification을 위해 trainable classifier를 거친다.
Yolo는 앞서 정리한 것을 참고하면 좋을 것 같다.
간단히 리뷰하자면,
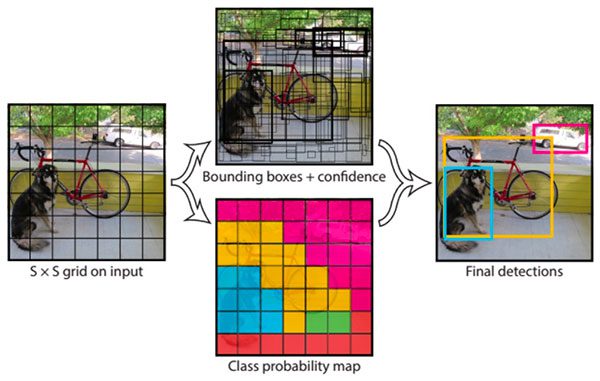
bounding box regression 과 classification을 나눠서 진행하는 Two stage 방법과는 다르게 두 개를 합쳐 동시에 진행함으로써 속도를 향상시켰다.
이미지를 SxS 그리드로 나누고, 이미지가 있을 법한 곳에 bounding box를 여러 개 예측하고, 각 BB에 대한 confidence를 추출한다. 이 confidence는 box안에 클래스가 존재하는지에 대한 파라미터다.
two stage 보다 속도는 뛰어나지만, 정확도 면에서는 떨어진다.
What is the YoloV5
train YOLOV5 using Custom dataset(open image dataset)
1
2
3
4
5
6
7
> Index
1. Preparing Dataset
2. Environment Setup
3. Configure / Modify files and directory structure.
4. Training
5. Inference
6. Result
- preparing dataset
open image dataset를 활용하여 분석할 것이다.
다운 받은 데이터셋을 train, validation, test txt files 로 생성하여 각각에 70%, 20%, 10% 로 이동시킨다. 이 때, txt 내용은 사진의 경로를 넣는다.
ex) ../data/train/000.jpg
- environment setup
git clone 을 통해 불러온 가상환경에서 진행한다. 그리고, requirement.txt 파일을 불러와 패키지 설치를 통해 환경을 설정한다.
$ git clone https://github.com/ultralytics/yolov5.git
$ cd yolov5
$ pip install -r requirement.txt
1
2
3
4
5
6
7
8
9
10
11
12
13
# requirement.txt
numpy==1.17
scipy==1.4.1
cudatoolkit==10.2.89
opencv-python
torch==1.5
torchvision==0.6.0
matplotlib
pycocotools
tqdm
pillow
tensorboard
pyyaml
- Configure / Modify files and idrectory structure

clone을 통해 불러온 것을 위와 같이 경로를 설정한다.
데이터셋의 parameter를 설정하기 위해서는 YAML 파일을 설정해야 한다. 필요에 따라 수정할 수 있다.
원래의 형태는 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../coco128/images/train
val: ../coco128/images/val
# number of classes
nc: 80
# class names
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
이를 자신이 cumtomize 하여 사용할 것만 가져오면 된다. 그리고 train, val 부분을 이미지가 있는 경로로 설정한다.
1
2
3
4
5
6
7
8
# here you need to specify the files train, test and validation txt # files created in step 1.
train: ./data/images/train
val: /data/images/valid
test: /data/images/test
# number of classes in your dataset
nc: 1
# class names
names: ['Elephant']
그 후 이미지를 작업 폴더로 옮기고, 각각 train, val, test 폴더로 분리시킨다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from glob import glob
import shutil
import os
data =['train','valid','test']
for i in data:
source = './data/iamges/' + i + '/'
image = './data/images/' + i
labels = './data/labels/' + i
mydict = {
image: ['jpg','png','gif','jpeg','JPG'],
labels: ['txt','json']
}
for destination, extensions in mydict_items():
for ext in extensions:
for file in glob(source +'*' + ext):
shutil.move(file, os.path.join(destination, file.split('/')[-1]))
- training
yolov5는 4가지로 나눌 수 있다. s,m,l,x 는 각각 small,medium, large, xlarge 에 해당한다.
이를 나눈 기준은 model depth multiple 과 layer width multiple 의 차이이다.
학습할 때 weight는 yolov5s.pt 라는 미리 학습되어 있는 파일을 사용한다.
| Model | size(pixels) | mAP-val 0.5:0.95 | mAP-test 0.5:0.95 | speed V100 (ms) |
|---|---|---|---|---|
| YOLOv5s | 640 | 36.7 | 36.7 | 2.0 |
| YOLOv5m | 640 | 44.5 | 44.5 | 2.7 |
| YOLOv5l | 640 | 48.2 | 48.2 | 3.8 |
| YOLOv5x | 640 | 50.4 | 50.4 | 6.1 |
이제 image를 train 모델에 입력시켜 훈련한다.
model을 학습하기 전, 사용할 model 파일을 들어가 nc(number of classes) 파라미터를 앞서 설정했던 것과 동일하게 변경시켜줘야 한다.
- Inference
훈련된 모델에 test image를 넣어 inference를 진행한다.
python3 detect.py --source ~/test_img/2011_09_26_drive_0091_sync/image_01/data/ --weights ./runs/exp5_ep50/weights/my_best.pt
detect.py를 통해 test를 하고 –source는 test할 data의 파일 경로 , –weights는 train에서 나온 결과 파일에서 weight 파일을 선택한다. weight file은 best.pt와 last.pt 가 나오는데 나는 best.pt 로 설정했다.
- Result

train YOLOV5 using Custom dataset(COCO dataset)
추가적으로 COCO Dataset을 사용할 경우를 보자. 위 사이트를 들어가면 coco dataset을 다운받을 수 있다.
여기서 coco dataset을 yolo dataset으로 변경시켜줘야 한다. 변경하는 방법은 직접 변경해도 되지만, 변경해주는 사이트가 따로 있다. 이 링크로 들어가서 jar 파일을 다운 받고 아래와 같이 입력하면 된다.
cocotoyolo.jar "json file(annotations) path" "img path" "class" "save path"
coco dataset을 다운 받을 때 annotation.json 의 위치, 변환할 이미지의 위치, 그리고 내가 원하는 추출하고자 하는 class 이름, 그리고 저장할 위치이다.

coco는 기본적으로 bounding box가 맨 왼쪽의 x,y 좌표로 구성되어 있고, 이에 따른 w,h 로 구성된다.

yolo dataset은 x,y 좌표가 bounding box 중앙에 위치하고, 이에 따른 w,h가 존재해야 한다. 따라서 x,y,w,h 좌표를 중앙을 기준으로 하도록 재설정해야 한다.
이후에는 open image dataset을 할 때와 같다.
1
2
3
4
5
6
> 성능 높이는 방법
yolov5 공식 깃허브에 기재되어 있는 성능 높이는 여러 방법이 있다.
* background image 넣기 => bg image를 넣으면 false positive가 줄어든다고 한다. train 이미지 전체의 0~10% 정도 넣어주는 것을 추천한다.
* pretrained weight 사용하기 => 작거나 중간 정도의 사이즈의 데이터셋 사용 시 추천한다. (yolov5.pt 대신 다른 것을 넣는 것이다.)
* epoch 을 300부터 시작해서 overfitting 이 발생하면 줄이고 아니면 점차 늘린다.
* 기본 파라미터들은 hyp.scatch.yaml에 있다. 먼저 이 parameter들을 학습시켜놓는 것을 추천한다. yolov5에서는 hyperparameter evolution 이라는 기법을 사용한다. 이는 genetic algorithm(GA)를 사용해서 hyperparameter를 최적화한다. 이 기법은 [이 블로그]를 참고하는 것이 좋다. 인자값으로 --evolve를 줘서 이 기법을 사용할 수 있다고 한다.
평가 지표
- IoU
IoU 는 데이터셋에 대해서 객체 검출하는 모델의 정확도를 측정하는 방법이다. 이는 합성곱 신경망을 사용한 객체 검출 모델(R-CNN, YOLO) 등에 사용된다. IOU를 평가하기 위해서 GT Bounding box와 모델로부터 예측된 bounding box 를 사용한다.

classification의 경우 라벨 값만 비교하면 되지만, 객체 검출은 bounding box를 정확하게 예측했는지가 중요하다. 따라서 bounding box의 x,y 좌표를 사용해야 한다.
이 때, threshold를 설정하여 0.5라고 가정하면 IOU를 계산했을 때, 0.5보다 큰 것만 가져온다.
- Precision, Recall
Precision(정밀도)는 모델이 예측한 결과의 positive 결과가 얼마나 정확한지 측정하는 것이고, Recall(재현율)은 모델이 예측한 결과가 얼마나 positive 값들을 잘 찾는지 측정하는 것이다.
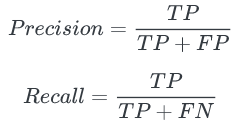
예를 들어, 암 진단의 경우를 볼 때,
precision: 양성으로 예측된 것 중 진짜 양성의 비율 => 모델이 정답이라고 한 것 중 진짜 정답의 비율 recall: 진짜 양성 중 양성으로 예측된 비율 => 진짜 정답 중에 모델이 정답이라 한 것의 비율

precision 과 recall 은 반비례하는 경향이 있다. 따라서 두 값을 종합해서 알고리즘 성능을 평가해야 한다. 그래서 나온 것이 PR곡선(Precision-recall)이다.
PR곡선은 confidence 에 따라 값이 변한다. confidence는 알고리즘이 검출한 것에 대해 얼마나 정확하다고 생각하는지 알려주는 값인데, 어떤 물체를 검출했을 때 confidence가 0.99라면 알고리즘은 그 물체가 검출해야 하는 물체와 거의 똑같다고 생각한다.
- Average Precision(AP) PR 곡선은 알고리즘의 성능을 평가하기에는 좋으나 서로 다른 두 알고리즘을 비교하는데는 좋지 않다.
Average precision은 PR그래프에서 그래프 선 아래쪽의 면적에 해당한다. AP가 높을수록 그 알고리즘의 성능이 높다는 뜻이다. 컴퓨터 비전에서는 대부분 AP로 성능을 평가한다.
- mAP(mean AP) mAP를 구하기 위해서 예측한 모든 bounding box를 가져온다. 이 모든 box를 confidence 기준으로 내림차순한다. 이 모든 box 에 대해 precision, recall 을 계산한다. 계산한 값들로 PR곡선을 그린다. 그 후 곡선 아래의 면적을 계산하면 된다. 객체가 두 개 이상일 경우 AP를 평균 낸다. 그래서 mAP인 것이다. 이때 mAP 0.5:0.05:0.95라고 하는 것은 0.5,0.05,0.95 IOU threshold를 사용하여 계산한 것이다.
diffence between YoloV5 and others
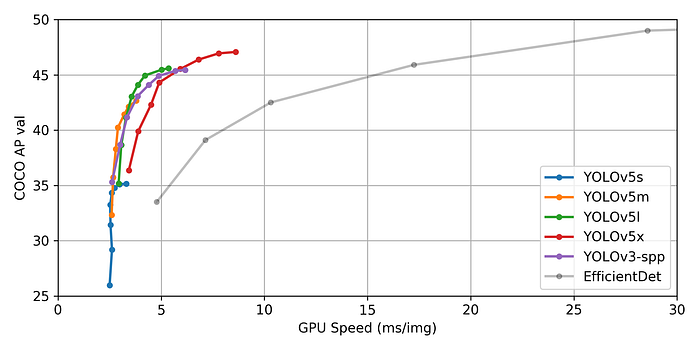
The First Release of model in pytorch between Yolo famliy yolov5는 처음으로 pytorch에서 구현되었기 때문에, 이 모델을 사용할 때, 보다 더 쉬워졌다. 또한, 모델을 ONNX 나 CoreML로 쉽게 컴파일할 수 있게 되었기 때문에 모바일 기기로의 구현이 간단해졌다.
More Faster and More Accurate and Small yolov5 colab 을 참고할 때, 140 frames per second(FPS)를 달성하였다고 한다. V4와 비교했을 때, 50FPS나 더 빨라진 것이다. 또한, 100 epochs 동안 평균 약 0.895 mAP 를 달성했다. yolov5의 weight 파일은 약 27MB 정도의 크기다. 그에 반해 yolov4는 244MB 이다.

Yolov5 Architecture
Backbone and Head
크게 Backbone과 Head가 있다.
yolov5가 빨라진 이유는 backbone의 변화의 영향이 가장 크다.
backbone의 경우, image로부터 feature map을 추출하는 부분인데, Yolov5는 DarkNet을 사용하고, CSPNet, 그 중에서도 BottleneckCSP를 사용했다.
CSPNet는 CNN의 학습 능력을 향상시키는 방법으로 이 블로그에 잘 설명되어 있다.
그리고, yolov5는 4가지로 나눌 수 있다. s,m,l,x 는 각각 small,medium, large, xlarge 에 해당한다.
Head의 경우, 추출된 feature map을 바탕으로 물체의 위치를 찾는 부분이다. Anchor box를 통해 bounding box를 예측한다. v3와 동일하게 3가지의 scale에서 바운딩 박스를 생성한다. 그 후, 각 scale마다 3개의 anchor box를 사용하기에 총 9개의 anchor box를 만들게 된다.
from n params module arguments
0 -1 1 3520 models.common.Focus [3, 32, 3]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 19904 models.common.BottleneckCSP [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 1 161152 models.common.BottleneckCSP [128, 128, 3]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 1 641792 models.common.BottleneckCSP [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 656896 models.common.SPP [512, 512, [5, 9, 13]]
9 -1 1 1248768 models.common.BottleneckCSP [512, 512, 1, False]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 378624 models.common.BottleneckCSP [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 95104 models.common.BottleneckCSP [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 313088 models.common.BottleneckCSP [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1248768 models.common.BottleneckCSP [512, 512, 1, False]
24 [17, 20, 23] 1 229245 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 191 layers, 7.46816e+06 parameters, 7.46816e+06 gradients
이는 yolov5의 전체 architeture 을 나타낸 것이다.
i가 0~9 까지가 backbone 10~24가 head 이다.
Backbone
model
Bottleneck
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
BottleneckCSP는 기본적으로 4개의 Conv layer를 생성한다.
이 중, conv2 와 conv3은 convolution + batch normalization을 진행한다.
또, CSP 구조이므로 y 값을 2 개 생성한다. y1은 conv1에서 바로 conv3로 갈 때의 연산값이 나오고, y2는 conv2의 값을 받는다. 이를 conv4에 합친 후 반환한다.
conv
conv + batch_norm 레이어다.
1
2
3
4
5
6
7
8
9
10
11
12
13
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.Hardswish() if act else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
forward 함수를 보면, 이 레이어는 conv 연산을 한 후에 batch normalization 과정을 거친다.
활성화 함수로는 Hard swish 함수를 사용한다. Hard swish는 최근에 나온 함수이다.

ReLU를 대체하기 위한 구글이 고안한 함수라고 한다. 시그모이드 함수에 x를 곱한 간단한 형태다. 깊은 레이어를 학습시킬 때 뛰어난 성능을 보인다고 한다.
SPP
Spatial Pyramid Pooling Layer 로, 55, 99, 13*13 feature map 들을 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
Concat
단순히 2개의 레이어 연산 값을 합치는 것이다.
1
2
3
4
5
6
7
8
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super(Concat, self).__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
Depth Multiple
depth multiple 값이 클수록 BottleneckCSP 모듈(레이어)가 더 많이 반복되어, 더 깊은 모델이 된다.
parse model
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
# print("depth_multiple : %s" %gd)
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
# print("depth_gain : %s" %n)
위의 코드를 보면, depth multiple 값이 gd라는 변수에 저장되는 것을 볼 수 있다. 변수 gd는 depth gain의 변수인 n을 구하는데 사용한다.
depth gain의 변수 n을 계산하기 위해서 2개으 변수를 사용한다. 위에서 설명한 gd(=depth_multiple) 값과 yaml 파일에서 number라고 적혀있는 n 값을 사용한다.
위의 yolov5 aritecture을 보면 Focus, Conv, SPP 모듈은 number 값이 1이고, bottleneckCSP 모듈만이 number 값을 3,9를 가진다.
number의 n과 depth_multiple 의 gd를 곱하고 round로 반올림 한 후, max 를 통해 정수 1보다 작은 것을 제거시켜서 n(=depth gain)을 계산한다.
이 n을 활용하여
1
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
n 값만큼 반복한다.
아래는 n=9인 BottleneckCSP의 구조다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
number : 9
depth_gain : 3
module : BottleneckCSP(
(cv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
(cv2): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(cv3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(cv4): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): LeakyReLU(negative_slope=0.1, inplace=True)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Hardswish()
)
)
)
)
여기서 핵심은 (n):Bottleneck 이다. n=9이고, depth_gain=3 일 경우
n * gd = 9 * (1/3) = 2.97 즉 3 정도이기 때문에 0~2 총 3번 반복한다.
Width Multiple
args값과 width_multiple 값을 곱한 값이 해당 모듈의 채널 값으로 사용된다. 즉, width_multiple 값이 증가할수록 해당 레이어의 conv필터 수가 증가한다.
yolov5s 의 경우 width_multiple 값은 0.5이다. 이 변수는 gw에 저장된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# yaml file
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
yolov5 의 backbone 구조를 나타낸 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
# print("depth_multiple : %s" %gd)
# print("width_multiple : %s" %gw)
if m in [nn.Conv2d, Conv, Bottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3]:
c1, c2 = ch[f], args[0]
# print("args [0] : %s" %c2)
c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
# print("make_divisible_c2 : %s" %c2)
################### utils 폴더 안에 있는 general.py 코드 ####################
def make_divisible(x, divisor):
# Returns x evenly divisble by divisor
return math.ceil(x / divisor) * divisor
이때 c2라는 변수도 존재하는데, yaml 파일의 args의 첫번째 변수다. Focus 에서 args로 [64,3]를 가지고 있다. 따라서 64가 c2 값이 된다.
gw와 c2는 make_divisible 함수에 의해 두 변수를 곱해서 계산된다.
Head
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# yolov5s.yaml
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# yolo.py result (YOLOv5-s'HEAD)
i from n params module arguments
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 378624 models.common.BottleneckCSP [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 95104 models.common.BottleneckCSP [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 313088 models.common.BottleneckCSP [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1248768 models.common.BottleneckCSP [512, 512, 1, False]
24 [17, 20, 23] 1 229245 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
head 또한 from number module arguments 로 구성되어 있다.
{conv,upsample,concat,bottleneckCSP}가 한 불록이다. 이 블록이 총 4개 있는 것이고, 마지막 detect 부분으로 연결된다.
Concat
여기서 concat의 의미는 바로 전 층인 nn.upsample 층과 bottleneckCSP 층과 결합시키는 것이다.
첫번째 concat 부분은 backbone의 P4(i=6인 BottleneckCSP)와 결합 두번째 concat 부분은 backbone의 P3(i=4인 BottleneckCSP)와 결합 -> 작은 물체 검출 세번째 concat 부분은 backbone의 P4(i=14인 conv)와 결합 -> 중간 물체 검출 네번째 concat 부분은 backbone의 P5(i=10인 conv)와 결합 -> 큰 물체 검출 한다는 것이다. P3가 작은 물체 검출인 이유는 P3의 경우 작은 픽셀을 가지고 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
elif m is Concat:
print("ch_list : %s" %ch)
for x in f:
if x == -1:
print("x : %s" %x)
print(ch[-1])
else:
print("x+1 : %s" %str(x+1))
print(ch[x+1])
c2 = sum([ch[-1 if x == -1 else x + 1] for x in f])
print("c2 : %s" %c2)
detect
말 그대로 i = 17,20,23 layer를 종합하여 detect 한다.
Loss
GIoU
GIoU는 bounding box에 관한 loss 함수다. 이는 compute_loss 함수에 있다. 1 - giou 값 = giou loss 이다.
1
2
giou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # giou(prediction, target)
lbox += (1.0 - giou).mean() # giou loss
GIoU 는 general.py 의 bbox_iou 함수에 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Intersection area
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1
union = (w1 * h1 + 1e-16) + w2 * h2 - inter
iou = inter / union # iou
if GIoU or DIoU or CIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if GIoU: # Generalized IoU https://arxiv.org/pdf/1902.09630.pdf
c_area = cw * ch + 1e-16 # convex area
return iou - (c_area - union) / c_area # GIoU
최종적으로 giou loss 는 utils/general.py의 compute_loss 함수에 있다.
(1 - giou 값 = giou loss) 이다.
obj ( objectness loss), cls(classification loss)
objectness loss와 classification loss는 BCEwithLogitsLoss를 사용한다. 이것도 general.py에 있다. BCEwithLogitsLoss는 class가 2개인 경우에 사용하는 loss function인 Binary Cross Entropy 에 sigmoid layer를 추가했다.
classcification loss는 객체 탐지가 제대로 탐지되었는지에 대한 loss이다. MSE와 유사하게 (판단 값-실제 값)^2 해서 구한다.
1
cls += BCEcls(ps[:,5:],t) # BCE
objectness loss는 객체 탐지에 대한 loss이다. 객체가 있을 경우의 loss 와 없을 경우의 loss를 따로 구하고, 각 loss에 가중치 값을 곱하여 클래스 불균형 문제를 해결한다.
1
2
3
4
5
6
7
# Losses
nt = 0 # number of targets
np = len(p) # number of outputs
balance = [4.0, 1.0, 0.4] if np == 3 else [4.0, 1.0, 0.4, 0.1] # P3-5 or P3-6
lobj += BCEobj(pi[..., 4], tobj) * balance[i] # obj loss
optimizer
default 값으로는 SGD, 추가 설정으로 Adam으로 설정이 가능하다.
