
KFold Cross Validation
교차검증이란 훈련 시 과적합을 막기 위해 사용하는 것이다. 교차검증은 훈련 데이터 셋을 학습 데이터와 검증 데이터 셋으로 분할하고, 훈련 데이터와 검증 데이터 셋을 교차하면서 검증한다.
학습셋과 검증셋을 나눠 반복해서 검증한다. k만큼의 폴드 셋으로 나누어 k번 반복한다. 그렇게 되면 최종 평가는 k만큼의 길이를 갖게 된다. 이를 평균 내어 평가한다.
평균을 구하는 방법으로는
- 모든 fold에 대해 epoch의 평균 절대 오차인 MAE(mean absolute error)의 오차 평균을 구한다.
- Validation MAE(y축), epochs(x축)을 갖는 그래프를 그려보고 그래프의 흐름을 보면 어디서 과대적합이 일어났는지 체크할 수 있다.
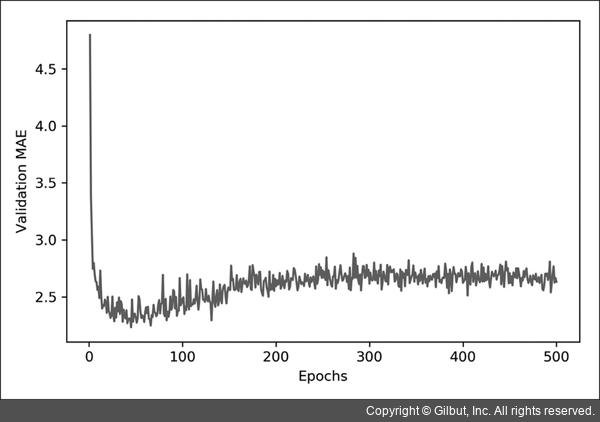
딥러닝에서 kfold를 사용하게 될 경우
- 데이터 검증 셋의 분할에 따른 검증 결과를 보고 어떤 데이터 셋이 과적합을 일으키는지 볼 수 있다. 이를 통해 과적합을 막을 수 있다.
- 검증 점수를 보고 epoch을 어떻게 구성해야 할지 알 수 있다.
- kfold를 쓰면 어느 지점에서 학습이 덜 되는지 알 수 있어 파라미터 값을 조절할 수 있다.
사용 하는 모듈 종류
1. Sklearn.model_selection.KFold
일단 k개의 fold로 나누고 index를 반환해보자.
1
2
3
4
5
6
7
8
9
10
11
12
from sklearn.model_selection import KFold
import numpy as np
x = np.arange(16).reshape((8,-1))
y = np.arange(8).reshape((-1,1))
kf = KFold(n_splits = 4, shuffle = False)
for train_index, test_index in kf.split(x):
print("train: ", train_index, "test: ", test_index)
x_train, x_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]
2. sklearn.model_selection.StratifiedKFold
데이터가 편향되어 있을 경우 단순 Kfold 교차검증을 사용하면 성능 평가가 좋게 나오지 않을 수 있다. 이럴 때 stratifiedkfold를 사용한다.
stratifiedKFold 함수는 매개변수로 n_splits, shuffle, random_state를 가진다. n_splits는 몇개로 분할할지를 정하는 매개변수이고, shuffle의 기본값 false 대신 true를 넣으면 fold를 나누기 전에 무작위로 섞는다. 그 후, cross_val_score 함수의 cv매개변수에 넣으면 된다. 일반적으로 회귀에는 kfold cross validation을 사용하고, 분류에는 stratifiedkfold를 사용한다.
또, cross_val_score 함수는 kfold의 매개변수를 제어할 수 없으므로 따로 kfold 객체를 만들고 매개변수를 조정한 다음 cross_val_score의 cv매개변수에 넣어야 한다.
y가 0,0,1,2,1,0,0,0,0,1,2,2 이다. 숫자를 어떤 label이라 생각하고 분포를 살펴보면
0이 6, 1이 3, 2가 3, 즉 2:1:1 분포를 가지고 있다. 그렇다면 fold들도 각각 label0, label1, label2를 2:1:1로 가져야 한다.

위의 이미지와 같이 label의 분포가 모두 같음을 볼 수 있다.
1
2
3
4
5
6
7
8
9
from sklearn.model_selection import StratifiedKFold
x = np.arange(12*2).reshape((12,-1))
y = np.array([0,0,1,2,1,0,0,0,0,1,2,2])
skf = StratifiedKFold(n_splits=3)
for train, test in skf.split(x, y):
print(train, test)
3. Cross_val_score
Cross_val_score 함수는 교차 검증을 더 편리하게 해주는 것이다. kfold과정을 한꺼번에 수행한다.
args로는 cross_val_score(estimator,x,y,scoring,cv,n_jobs=1, verbose=0,fit_params,pre_dipatch)
- x: image 데이터셋
- y: label 데이터셋
- scoring: 예측 성능 평가 지표
- cv: 교차 검증 폴드 수
수행 후 반환 값은 scoring 측정값을 배열 형태로 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score, cross_validate
from sklearn.datasets import load_iris
import numpy as np
iris = load_iris()
dt = DecisionTreeClassifier(random_state = 156)
features = iris.data
label = iris.target
scores = cross_val_score(dt, features, label, scoring='accuracy', cv=3)
print("\n교차 검증별 정확도: ", np.round(scores, 4))
print("평균 검증 정확도: ", np.round(np.mean(scores),4))
iris 데이터를 통한 kfold
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import numpy as np
iris = load_iris()
data = iris.data
label = iris.target
dt= DecisionTreeClassifier()
# 5개의 Fold로 분리하고 세트별 정확도를 담을 리스트 객체 생성
kfold = KFold(n_splits = 5)
cv_accuracy = []
n_iter = 0
# split()를 호출하면 fold별 학습용, 검증용 테스트의 행 인덱스를 array로 반환
for train_index, test_index in kfold.split(data):
x_train, x_test = data[train_index], data[test_index]
y_train, y_test = label[train_index], label[test_index]
# 학습 및 예측
dt.fit(x_train, y_train)
pred = dt.predict(x_test)
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred),4)
print(n_iter,"번쨰: ", test_index,"\n")
cv_accuracy.append(accuracy)
print("평균 검증 정확도: ", np.mean(cv_accuracy))
stratified kfold
불균형한 분포도를 가진 레이블 데이터 집합을 위한 kfold 방식
레이블이 1:100000의 비율을 가진 데이터라면 학습/테스트 셋에도 1:100000의 비율로 들어가 있어 제대로 예측하기가 힘들다. 이때 사용하는 것이 stratified kfold이다. 레이블의 분포를 균등하게 해주고 kfold를 진행한다.
그러나, iris 데이터에서는 레이블 value가 모두 동일하여 비교가 되지 않는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
iris = load_iris()
data = iris.data
label = iris.target
dt= DecisionTreeClassifier(random_state = 156)
df = pd.DataFrame(data=iris.data, columns = iris.feature_names)
df['label']=iris.target
df['label'].value_counts()
skfold = StratifiedKFold(n_splits=3)
n_iter = 0
cv_accuracy = []
for train_index, test_index in skfold.split(df, df['label']):
n_iter += 1
label_train = df['label'].iloc[train_index]
label_test = df['label'].iloc[test_index]
print("교차검증: ",n_iter)
print("학습 레이블 분포도: \n", label_train.value_counts())
print("검증 레이블 분포도: \n", label_test.value_counts())
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
from sklearn.model_selection import StratifiedKFold
iris = load_iris()
data = iris.data
label = iris.target
dt= DecisionTreeClassifier(random_state = 156)
skfold = StratifiedKFold(n_splits=3)
n_iter = 0
cv_accuracy = []
for train_index, test_index in skfold.split(data,label):
x_train, x_test = data[train_index], data[test_index]
y_train, y_test = label[train_index], label[test_index]
dt.fit(x_train, y_train)
pred = dt.predict(x_test)
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred),4)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
print("\n교차검증 정확도: {} 학습데이터 크기: {} 검증 데이터 크기: {}".format(accuracy, train_size, test_size))
print('검증 셋 인덱스: ',test_index)
cv_accuracy.append(accuracy)
print("\n교차 검증별 정확도: ", np.round(cv_accuracy,4))
print("평균 검증 정확도: ", np.mean(cv_accuracy))
image data에 kfold 적용해보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
''' 기본 구조 '''
stfold = StratifiedKFold(n_splits = 5, shuffle = True, random_state=800)
for idx, (train_idx, valid_idx) in enumerate(stfold.split(train_data ,train_data["digit"])):
train_data = total_data.iloc[train_idx]
valid_data = total_data.iloc[valid_idx]
train_dataset = dataset(train_data, tranforms["train"])
valid_dataset = dataset(valid_data, tranforms["val"])
train_dataloader = DataLoader(train_dataset, batch_size = bs, shuffle=True, drop_last = False)
valid_dataloader = DataLoader(valid_dataset, batch_size = bs, shuffle=False, drop_last = False)
for epoch in range(epoch+1):
model.train()
model.eval()
이 때의 val 비율은 k가 5이므로 4:1, 즉 20%
caltech data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
'경로, label을 담은 csv 파일 만들기'
cal_dir = '/content/drive/MyDrive/data/caltech_10'
train_dir = cal_dir + '/train'
test_dir = cal_dir + '/test'
classes = []
image_label = []
cn = 0
train_folders = glob(train_dir + '/*')
for train_folder in train_folders:
image_paths = glob(train_folder + '/*')
for image_path in image_paths:
image = image_path.split('/')[-2:]
image = image[0]+"/"+image[1]
image_label.append([image, cn])
cn += 1
train_folder = train_folder.split('/')[-1]
classes.append(train_folder)
image_label = pd.DataFrame(image_label, columns=['label', 'class_number'])
image_label.to_csv('/content/drive/MyDrive/data/caltech_10/train/train_label.csv', index=False)
1
pd.read_csv("/content/drive/MyDrive/data/caltech_10/train/train_label.csv")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
val_dir = cal_dir + '/valid'
cn = 0
classes = []
image_label = []
val_folders = glob(val_dir + '/*')
for val_folder in val_folders:
image_paths = glob(val_folder + '/*')
for image_path in image_paths:
image = image_path.split('/')[-2:]
image = image[0]+"/"+image[1]
image_label.append([image, cn])
cn += 1
val_folder = val_folder.split('/')[-1]
classes.append(val_folder)
image_label = pd.DataFrame(image_label, columns=['label', 'class_number'])
image_label.to_csv('/content/drive/MyDrive/data/caltech_10/valid/valid_label.csv', index=False)
1
pd.read_csv("/content/drive/MyDrive/data/caltech_10/valid/valid_label.csv")
CustomDataset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
''' caltech_10 data '''
import torch, torchvision
from torchvision import datasets, models, transforms
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import time
from torchsummary import summary
import numpy as np
import matplotlib.pyplot as plt
import os
from glob import glob
import pandas as pd
from PIL import Image
import random
from tqdm.notebook import tqdm
import warnings
warnings.filterwarnings('ignore')
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
seed = 42
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
cal_dir = '/content/drive/MyDrive/data/caltech_10'
train_dir = cal_dir + '/train'
valid_dir = cal_dir + '/valid'
test_dir = cal_dir + '/test'
train_csv = train_dir + '/train_label.csv'
valid_csv = valid_dir + '/valid_label.csv'
batch_size = 32
epochs = 20
num_classes = len(os.listdir(train_dir))
transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]) # 지금은 채널이 3이라 3개를 적지만, gray scale일 경우 ((0.5),(0.5)) 형태로 작성해야 함
]),
'valid': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
class CustomImageDataset(Dataset):
def __init__(self, csv_file, root_dir, transform = None):
self.label_dir = pd.read_csv(csv_file)
self.img_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.label_dir)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.label_dir.iloc[idx,0])
image = Image.open(img_path).convert('RGB')
label = self.label_dir.iloc[idx,1]
if self.transform:
image = self.transform(image)
return image, label
dataset = {
'train': CustomImageDataset(train_csv, train_dir,transforms['train']),
'valid': CustomImageDataset(valid_csv, valid_dir,transforms['valid'])
}
dataloader = {
'train': DataLoader(dataset['train'], batch_size = batch_size, shuffle = True),
'valid': DataLoader(dataset['valid'], batch_size = batch_size, shuffle = False)
}
for x_train, y_train in dataloader['train']:
print("x_train {} \ny_train {}\n\n".format(x_train.size(), y_train.size()))
break
import torchvision.models as models
model = models.densenet121(pretrained = True).to(device)
num_ftrs = model.classifier.in_features
model.fc = nn.Linear(num_ftrs, num_classes)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001, weight_decay = 0.0001)
''' train_valid 함수 정의'''
def train_and_val(model, criterion, optimizer, train_data, valid_data, epochs=25):
best_loss = 5
best_epoch = None
history = []
for epoch in tqdm(range(epochs)):
epoch_start = time.time()
model.train()
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
correct = 0
for i, (images, labels) in enumerate(train_data):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
predictions = outputs.max(1, keepdim = True)[1]
correct += predictions.eq(labels.data.view_as(predictions)).sum().item()
train_loss /= (len(train_data.dataset) / batch_size)
train_acc = 100. * correct / len(train_data.dataset)
correct = 0
with torch.no_grad():
model.eval()
for i, (images, labels) in enumerate(valid_data):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
valid_loss += criterion(outputs, labels).item()
predictions = outputs.max(1, keepdim = True)[1]
correct += predictions.eq(labels.data.view_as(predictions)).sum().item()
valid_loss /= (len(valid_data.dataset) / batch_size)
valid_acc = 100. * correct / len(valid_data.dataset)
if valid_loss < best_loss:
best_loss = valid_loss
best_epoch = epoch
print("best_loss: {:.4f} \n best_epoch: {}".format(best_loss, best_epoch))
history.append([train_loss,valid_loss, train_acc,valid_acc])
epoch_end = time.time()
print("Epoch : {:03d}, Training: Loss - {:.4f}, Accuracy - {:.2f}%, \n\t\tValidation : Loss - {:.4f}, Accuracy - {:.2f}%, Time: {:.4f}s".format(epoch, train_loss, train_acc, valid_loss, valid_acc, epoch_end-epoch_start))
return model, history, best_epoch
model, history, best_epoch = train_and_val(model, criterion, optimizer, dataloader['train'], dataloader['valid'], epochs=10)
CustomDataset + stratifiedKFold
customdataset의 args를 살짝 바꿔야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
class CustomDataset(Dataset):
def __init__(self, data, transform = None):
self.data_dir = data
self.transform = transform
def __getitem__(self, idx):
img_path = os.path.join(train_dir, self.data_dir.iloc[idx,0])
image = Image.open(img_path).convert('RGB')
label = self.data_dir.iloc[idx,1]
if self.transform:
image = self.transform(image)
return image, label
def __len__(self):
return len(self.data_dir.iloc[:,1])
train_csv_data = pd.read_csv(train_csv)
stfold = StratifiedKFold(n_splits = 5, shuffle=True, random_state=seed)
for idx, (train_idx, valid_idx) in enumerate(stfold.split(train_csv_data, train_csv_data.iloc[:,1])):
train_data = train_csv_data.iloc[train_idx]
valid_data = train_csv_data.iloc[valid_idx]
stf_dataset = {
'train': CustomDataset(train_data, transforms['train']),
'valid': CustomDataset(valid_data, transforms['valid'])
}
stf_dataloader = {
'train': DataLoader(stf_dataset['train'], batch_size = batch_size, shuffle = True),
'valid': DataLoader(stf_dataset['valid'], batch_size = batch_size, shuffle = False)
}
#print("학습 레이블 분포도: \n", train_data.iloc[:,1].value_counts())
#print("검증 레이블 분포도: \n", valid_data.iloc[:,1].value_counts(),"\n\n")
model, history, best_epoch = train_and_val(model, criterion, optimizer, stf_dataloader['train'], stf_dataloader['valid'], epochs=5)
stratifiedKFold를 적용할 경우 98~99% 정도의 valid acc를 볼 수 있다.
