

Deep Sort에 대한 논문을 리뷰한 내용입니다. 혼자 공부하기 위해 정리한 내용으로 이해가 안되는 부분들이 많을 거라 생각됩니다. 참고용으로만 봐주세요.
Abstract
SORT 는 간단하고 효과적인 알고리즘에 초점을 맞춘 Multiple Object Tracking 에 대한 실용적인 접근이다. 하지만 평가 불확실성(estimation uncertainty)이 낮을 때만 association metric이 정확하여 객체가 계속 스위칭 되는 현상이 있었다. 즉, (가려짐)occlusion에 취약했다.
본 논문에서는 SORT 의 성능을 향상시키기 위해 appearance information 즉, 외형 정보를 통합한다. 이를 통해, 더 긴 기간동안 가려졌던 물체를 추적하고, ID 스위칭 수를 줄일 수 있다.
또한, 복잡한 계산을 offline pretraining 단계에 배치하여, 큰 스케일의 person re-identification dataset 에서 deep association metric을 학습한다.
online을 적용하면서, visual appearance 에 대해 nearest neighbor를 사용하여 measurement-to-track association을 만들었다.
실험을 통해 ID 스위칭 수가 45%까지 감소할 수 있었고, 높은 프레임률로 좋은 성능을 달성했다.
이때,
online과offline학습의 차이는
- online: mini batch라 부르는 작은 묶음 단위로 훈련한다. 연속적으로 데이터를 받고 빠른 변화에 스스로 적응해야 하는 시스템에 적합하다.
- offline : 가용한 데이터를 모두 사용해 훈련시킨다. 시간과 자원을 많이 소모하기 때문에 오프라인에서 가동된다. 시스템을 훈련시키고 적용하면 더 이상 학습 없이 실행 가능하다. 하지만 새로운 데이터에 대해 학습하려면 전체 데이터를 사용하여 시스템의 새로운 버전을 만들어 처음부터 다시 훈련해야 한다.
Introduction
최근 object detection의 진보로 인해, tracking-by-detection은 Multiple Object Tracking에서 앞서나가는 패러다임이 되었다.
이 패러다임에는 객체 궤적은 보통 전체 video batch들을 한 번에 처리하는 전역 최적화 문제(global optimization problem)가 존재했다. 이 batch processing 때문에, 이 방법은 각 시간마다 대상 ID가 반드시 이용가능해야 하는 온라인 방식에는 적용될 수 없었다.
전통적인 방법인 MHT(Multiple Hypothesis Tracking) 과 JPDAF(Joint Probabilistic Data Association Filter)은 frame-by-frame 방식을 사용하여 data association을 수행한다.
JPDAF에서 단일 state hypothesis 는 data association 에 따라 개별 측정값에 가중치를 부여하여 발생된다. 또, MHT에서는 가능한 모든 hypotheis를 추적하지만 계산 추적성을 위해 pruning schemes를 적용해야 한다. 두 방법은 최근 tracking-by-detection 에서 재검토되어 좋은 결과를 보여줬다.
하지만, 두 방법의 성능은 계산 및 구현 복잡성을 증가시키게 된다.
SORT는 이미지 공간에서 kalman filtering을 수행하고 bounding box overlap을 측정하는 association metric과 함께 Hungarian method를 사용하여 frame-by-frame data association을 수행하는 간단한 프레임워크다. 이 간단한 방법은 높은 프레임율을 달성했다.
MOT challenge dataset에서, 최첨단 detector가 있는 SORT가 표준 detector의 MHT보다 높은 순위를 차지한다.
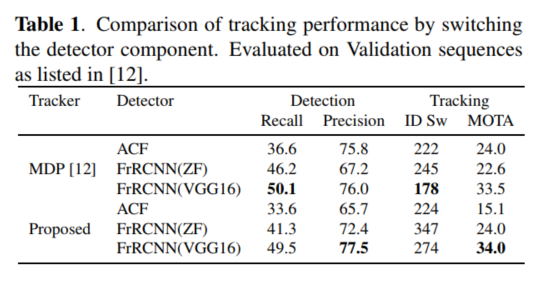
이유는 지난 번 리뷰에도 봤듯이 좋은 detector 가 좋은 tracking 성능을 만들기 때문이다.
SORT는 tracking precision 과 accuracy 측면에서 전반적으로 우수한 성능을 보이지만, 상대적으로 높은 ID(identity) 스위칭을 반환한다. SORT에 사용된 association metric이 상태 추정 불확실성(state estimation uncertainty)이 낮을 때만 정확하기 때문이다.
또한, SORT는 일반적으로 전면 카메라 장면에서 나타나기 때문에 occlusion을 추적하는 데 결함이 있다.
그래서 data association을 motion과 appearance information을 결합하여 더 많은 정보를 가진 metric으로 대체함으로써 이 문제를 해결한다.
특히 large-scale의 person re-identification dataset에서, 보행자(pedestrians)를 식별하도록 훈련된 CNN(Convolutional Neural Network)을 적용하고자 한다.
CNN을 통해 시스템을 구현하기 쉽고 효율적이며 온라인 방식에 적용할 수 있도록 유지하면서 오류와 occlusion에 대해 견고함을 향상시켰다.
SORT with Deep Association Metrics
본 논문에서는 반복적인 Kalman filtering과 frame-by-frame data association을 가진 single hypothesis tracking 방법을 선택한다.
이 시스템의 핵심 구성 요소에 대해 설명하고자 한다.
Track Handling and State Estimation
SORT와 동일하게 등속 운동과 선형 관측 모델이 있는 kalman fiter와 Hungarian algorithm을 사용하지만, state space의 형태가 달라졌다. 카메라가 보정되지 않은 상태거나 이용할 수 있는 ego-motion information이 없는 일반적인 tracking 시나리오로 가정한다.
이러한 상황은 filter 프레임워크에 문제를 야기하지만, 최근 MOT benchmark에서는 가장 기본적인 설정이다.

그래서 우리의 tracking 시나리오는 위와 같이 총 8개 차원의 상태 공간으로 정의된다.
(u,v): bounding box 의 중심 위치r: 가로 세로 비율h: 높이(x,˙ y,˙ γ,˙ h˙):이미지 좌표의 속도
이미지의 좌표는 object state의 직접 관측을 통해 얻은 값을 사용한다.
각 track K는 measurement association 될 때마다 프레임의 수를 카운트되며, 이 카운트는 kalman filter prediction하는 동안에 증가되고, track이 measurement와 연결되면 0으로 재설정된다.
사전정의된 Max age 보다 오래 매칭되지 않은 track은 화면을 떠난 것으로 간주되어 삭제한다.
기존 트랙과 연관(association)될 수 없는 각 detection에 대해서는 새로운 track 가설(hypothesis)를 시작한다. 이 새로운 track은 처음 3번의 프레임까지는 잠정적(tentative) 상태로 분류하여 매칭되지 않아도 연관되기 전까지 유지하고, 그래도 안되면 삭제한다.
Assignment Problem
예측된 kalman state와 새로 받은 측정치(measurement) 사이의 연관성(association)을 해결하는 전통적인 방법은 Hungarian algorithm을 사용하여 해결할 수 있는 할당 문제(assignment problem)를 구축하는 것이다.
이 문제 공식에서 두 가지 적절한 metric의 조합을 통해 motion과 appearance information을 통합한다.
motion 정보를 통합하기 위해 예측된 kalman state와 새로 받은 측정치 사이의 Mahalanobis distance를 사용한다.
- Mahalanobis Distance

(yi,Si): i번째 track distribution에서 측정 space로의 예상치(projection)(dj): j번째 bounding box detection- i번째 track과 j번째 bounding box detection 사이의 거리
Mahalanobis distance는 detection이 평균 track location으로부터 표준편차에 대해 얼마나 떨어져 있는지를 측정하여 state estimation uncertainty를 계산하는 것이다.

이것은 inverse X² 분포의 95% 신뢰구간만 고려하여 해당되지 않는 association은 배제시키는 방법이다.
i번째 track과 j번째 detection 사이의 연관성이 인정되면 1을 출력한다.
4차원 measurement space의 경우 Mahalanobis threshold, t(1) = 9.4877 이다.
Mahlanobis distance 는 motion uncertainty가 낮을 때는 적절한 association metric 가 된다.
Mahalanobis distance는 short-term prediction에 유용한 움직임에 기초하여 가능한 object location에 대한 정보를 제공한다.
하지만 kalman filtering 프레임워크에서 얻은 예측 state 분포는 객체 위치의 대략적인 추정치만 제공한다. 특히, 설명되지 않은 카메라 모션으로 인해 이미지 평면에 빠른 변위가 발생할 수 있으므로 이것을 해결하기 위해 Cosine distance를 도입했다.
Mahalanobis distance에 대해 블로그에 있는 것을 추가해보았다. Mahalanobis distance: 평균과의 거리가 표준편차의 몇 배인지를 나타내는 값
위의 그림을 보면 일반적인 거리 개념으로 볼때, a가 μ에 더 가깝다.
하지만, 데이터들의 평균을 중심으로 데이터의 분산이 가장 큰 방향을 기준으로 축을 잡고 표준편차를 이용하여 계산하게 된다. 이 때 축은 점의 약 68%가 한 단위 내, 95%는 두 단위 내에 분포하도록 단위를 설정한다. 이렇게 설정하면 b가 더 가깝게 설정된다.
- reference : https://kimyo-s.tistory.com/46
 위의 그림을 보면 일반적인 거리 개념으로 볼때, a가 μ에 더 가깝다.
위의 그림을 보면 일반적인 거리 개념으로 볼때, a가 μ에 더 가깝다.  하지만, 데이터들의 평균을 중심으로 데이터의 분산이 가장 큰 방향을 기준으로 축을 잡고 표준편차를 이용하여 계산하게 된다. 이 때 축은 점의 약 68%가 한 단위 내, 95%는 두 단위 내에 분포하도록 단위를 설정한다. 이렇게 설정하면 b가 더 가깝게 설정된다.
하지만, 데이터들의 평균을 중심으로 데이터의 분산이 가장 큰 방향을 기준으로 축을 잡고 표준편차를 이용하여 계산하게 된다. 이 때 축은 점의 약 68%가 한 단위 내, 95%는 두 단위 내에 분포하도록 단위를 설정한다. 이렇게 설정하면 b가 더 가깝게 설정된다.- Cosine distance
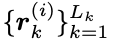
각 bounding box detection dj에 대해 절대값이 1인 appearance descriptor, rj 를 계산한다.
각 track k에 대해 마지막 100개의 appearance descriptor를 갤러리인 Rk에 보관한다.
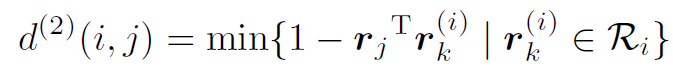
appearance descriptor는 사전 훈련된 CNN을 통해 구한다. 이것에 대해서는 section 2.4에 더 자세히 설명하겠다.
그리고 나서, 이 두번째 측정지표는 appearance space에서 i번째 track과 j번째 detection 사이의 제일 작은 cosine distance를 구한다.
또, 측정 지표에 따라 연관성이 허용되는지에 대한 여부를 나타내는 이진 변수를 소개한다.
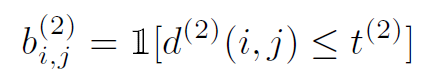
cosine distance는 움직임이 덜 차별적인(discriminative)한 경우 long-term occlusion 후 ID(identity)를 회복하는데에 유용한 appearance 정보를 다룬다.
따라서, 위의 두 distance를 결합하면 두 지표가 서로 다른 assignment 문제를 처리함으로써 상호 보완된다.

assignment problem을 구축하기 위해 두 metric를 가중치를 주면서 합한다.

두 측정지표의 gating 영역 내에 있을 경우 연관성이 있다고 인정된다.
실험에서 보면 Camera motino이 클 때 ⋋ = 0 으로 설정하는 것이 효과가 좋았기에, 이때는 Mahalanobis, d⑴은 gating(연관성 cost)에만 사용된다.
- Matching Cascade
전역 할당 문제(global assignment problem)에서 measurement-to-track association을 해결하기보단, 이 문제를 해결하기 위해 cascade를 도입했다.
물체가 오랫동안 가려지면 kalman filter는 uncertainty를 증가시켜 확률분포는 퍼지는 모양을 보인다.
이 때, Mahalanobis distance는 어떤 detection에 대해서도 표준편차로 계산한 거리가 작아지기 때문에 uncertainty가 높은 것을 선호한다.
하지만 이것은 바람직하지 않기 때문에 더 적은 수명을 갖는, 즉 uncertainty가 작은 track에게 우선순위를 부여한다. 부여하는 방법으로 matching cascade를 도입했다.

1.detection과 track 사이의 cost matrix 계산 2.detection과 track 사이에서 cost를 기반으로 threshold를 적용하기 위한 마스크 만들기 3.mask matrix 초기화 4.unmatched detection에 대한 matrix를detection으로 초기화(매칭 시 제거) 5.나이가 증가하는 트랙에 대한 선형 할당 문제를 해결하기 위해 모든 age에 대해 for문을 진행 6.마지막 n개 프레임에서 detection이랑 associate 되지 않은 track Tn의 부분집합을 선택 7.Tn안의 track과, 매칭되지 않은 detection U 사이의 최소 cost를 구해서 매칭 8.마스크의 threshold를 적용한 후 match matrix에 넣기 9.조건에 따라 unmatched matrix를 제외시킨다. 10.match matrix와 unmatched matrix를 return 한다.
위 과정을 거친 후 age==1인 unmatched and unconfirmed tracks와 unmatched detection 사이의 IoU association을 적용한다. 갑작스러운 appearance change를 구하는데 도움을 주기 때문이다.
- Deep Appearance Descriptor
간단한 nearest neighbor 방법을 사용하면서, 위의 방법들을 성공적으로 수행시키기 위해서는 실제 online tracking application을 하기 전에, offline에서 훈련을 통해 특징을 잘 구별할 수 있도록 만들어야 한다.
이를 위해 우리는 1261명의 보행자에 대한 11만 개 이상의 이미지를 포함하는 large-scale re-identification dataset(MARS)에 대해 pretraine된 CNN을 사용한다.
이것이 곧 deep metric learning 에 해당되는 것이다.

CNN Architecture은 아래 표와 같다.
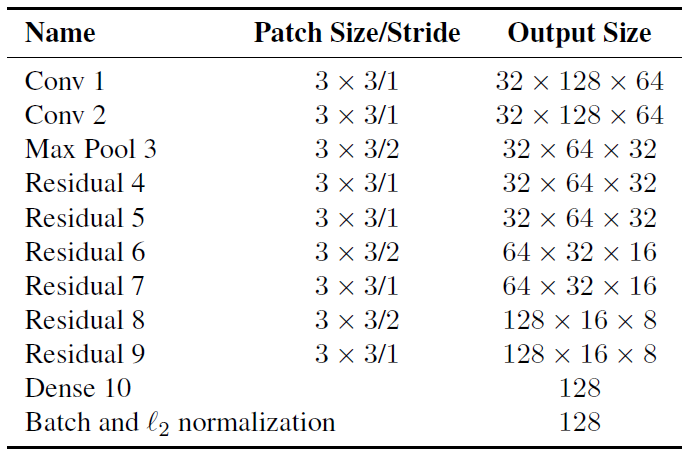
표를 보면,두 개의 convolutional layer과 여섯 개의 residual 블록을 가진 큰 residual network를 사용하는 ResNet 구조를 가진다.
결과적으로 전체 feature map은 차원 128의 크기를 가지고, dense layer 10에서 계산된다.
마지막에 batch와 L2 normalization에서는 정규화를 통해 cosine appearance metric와 호환될 수 있도록 features을 재해석한다.
이 네트워크에는 총 280만 개의 매개변수를 가지고 있다.
Experiments
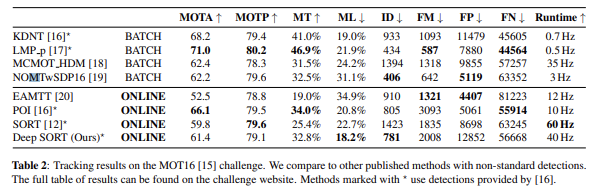
우리는 MOT16 benchmark에서 움직이는 카메라와 하향식 감시 설정을 포함한 7가지의 까다로운 테스트 시퀀스에서의 tracking 성능을 평가했다.
tracker의 입력은 detector에 의존했고, 뛰어난 성능을 보이기 위해 수많은 dataset을 통해 Fast RCNN을 훈련시켰다.
공정한 비교를 위해 동일한 detection에서 SORT를 다시 진행했다.
평가는 ⋋ = 0 및 Amax = 30 frame을 사용하여 수행했고, detection의 threshold = 0.3 을 사용했다.
benchmark에서 제공하는 매개변수로는 :
- MOTA(↑) : 다중 객체 tracking accuracy
- MOTP(↑) : 다중 객체 tracking precision
- FAF(↓) : 프레임 당 잘못 판정된 수
- MT(↑) : 주로 추적되는 궤적의 수. 즉, 타겟은 수명의 최소 80%에 대해 동일한 레이블
- ML(↓) : 대부분 손실된 궤적의 수. 즉, 타겟의 수명의 최소 20% 동안 추적되지 않은 레이블
- ID SW(↓) : ID가 다른 객체로 전환된 횟수
- Frag(↓) : miss detection에 의해 추적이 중단된 fragmentation 수
(↑) 는 점수가 높을수록 좋은 성능을 나타내고, (↓) 는 반대다.
실험 결과 Identity switches를 1423개에서 781개, 약 45%를 성공적으로 줄였다.
동시에 occlusion과 miss인 객체도 제거하지 않고 인식함으로써 객체 identity가 유지되면서 track fragmentation도 약간 증가했다.
외형 정보 통합(appearance informantion integration)으로 인해, 더 긴 occlusion에도 identities를 성공적으로 유지했다.
deep sort는 다른 tracker과 비교하더라도 좋은 성능을 유지하면서 모든 online 방법 중 가장 적은 ID 스위치를 반환한다.
또한, 상대적으로 큰 maximum track age를 설정함으로써 더 많은 양의 track들이 제거되지 않고, 물체 궤적에 결합된다.
잘못 판단된 track이 감소되었으며, 비교적 안정적인 고정 track들을 생성한다.
Conclusion
pretrained association metric을 통해 appearance information을 통합하는, SORT의 확장인 deep sort를 제시했다. 그 결과 더 오랜 기간 동안 occlusion 상태를 추적할 수 있었다.
Refernece
- Simple Online and Realtime Tracking With A Deep Association Metric (21 Mar 2017) Nicolai Wojke, Alex Bewley, Dietrich Paulus page : https://arxiv.org/abs/1703.07402v1
- https://velog.io/@kimkj38/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-Deep-SORTSimple-Online-and-Realtime-Tracking-with-a-Deep-Association-Metric
- https://kau-deeperent.tistory.com/84
- https://kimyo-s.tistory.com/46
코드
- github https://github.com/ZQPei/deep_sort_pytorch#training-the-re-id-model
- github https://github.com/nwojke/deep_sort
- blog https://minding-deep-learning.tistory.com/6
- blog https://jjeamin.github.io/posts/deepsort/
